KSQLDB Stream & Table
Stream 개요
- stream은 메시지 streaming 처리를 위해서 추상화한 layer
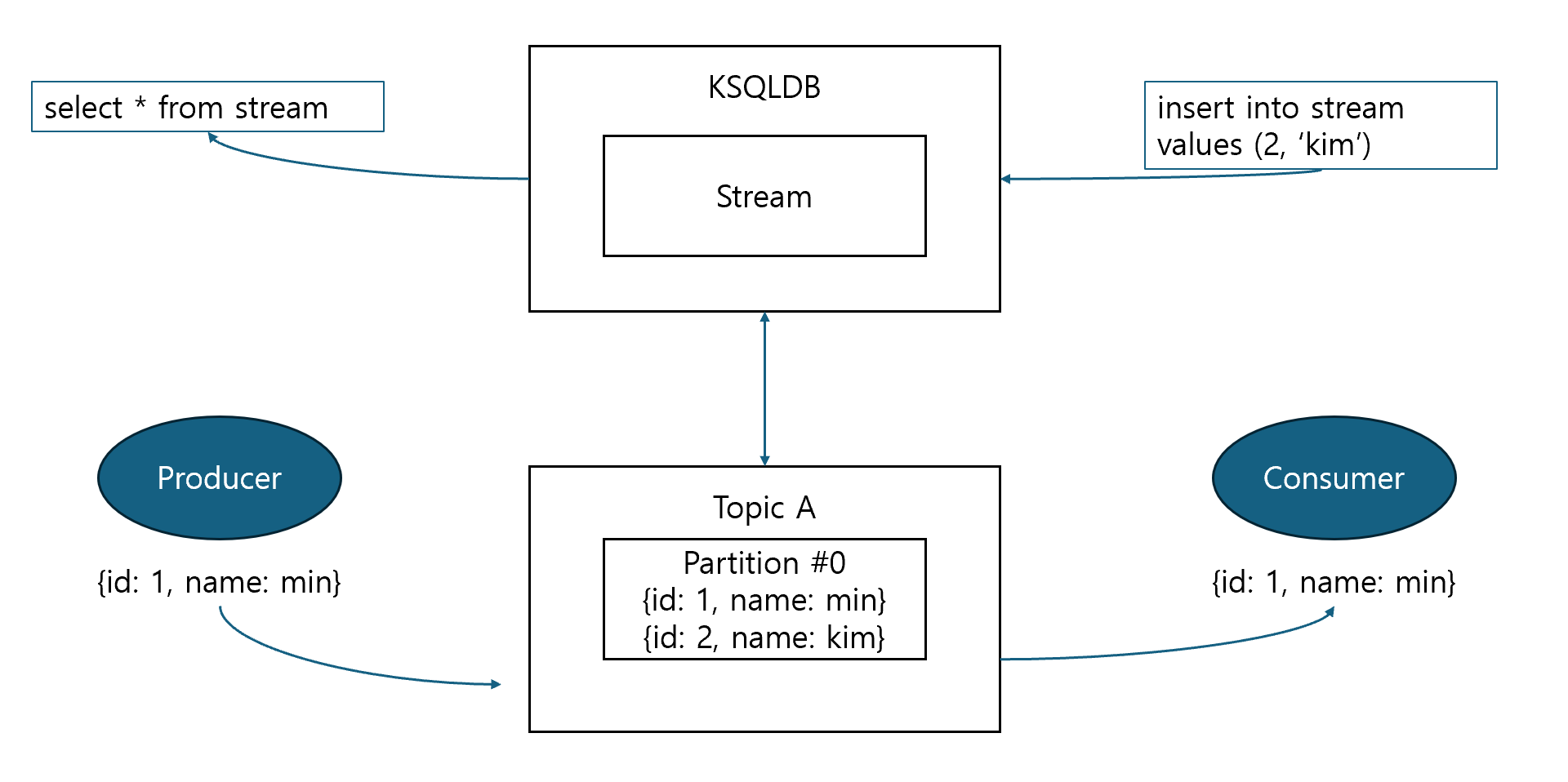
- 변경 불가하며 append만 가능한 collection
- 연속된 historical 정보 표현
- insert된 row는 변경 불가하며 (update, delete 불가) 새로 insert된 row는 stream의 마지막에 추가됨
- stream은 key를 가질 수도 그렇지 않을 수도 있으며 동일한 key 값을 가진 row는 동일한 파티션에 저장됨
Stream / Table 연속 처리
- stream과 table은 topic을 source로 할 수 있으며, 다른 stream 또는 table을 source로 입력 받아 연속적인 processing 가능
Stream과 Table 차이
- stream은 key 값의 중복 여부와 상관 없이 연속적으로 메시지 관리 (stateless)
- table은 primary key로 중복을 허용하지 않으며 동일 primary key로 메시지가 입력될 경우 해당 값을 업데이트 함 (stateful)

실습
토픽 생성
kafka-topics --bootstrap-server localhost:9092 --create --topic simple_user_stream
토픽에 메시지 전송
kafka-console-producer --bootstrap-server localhost:9092 --topic simple_user_stream
> {"id":1, "name":"name1", "email":"email1"}
{"id":2, "name":"name2", "email":"email2"}
{"id":3, "name":"name3", "email":"email3"}
{"id":4, "name":"name4", "email":"email4"}
stream 생성 및 select로 스트림 조회
create stream simple_user_stream
(
id int,
name varchar,
email varchat
) with
(
kafka_topic = 'simple_user_stream',
value_format = 'JSON'
);
select * from simple_user_stream;
- with 절은 topic과 format에 대한 설정 부과 가능
- 만약 기존 토픽이 없는 경우 새롭게 생성하는데 이 때 반드시 with 절에 partitions 옵션으로 파티션 개수 지정해야함
show streams; // stream 목록 확인 drop stream simple_user_stream delete topic; // stream 삭제하며 topic 함께 삭제
key를 가지는 stream 생성
create stream simple_user_stream
(
id int key,
name varchar,
email varchar
) with (
kafka_topic = 'simple_user_stream',
key_format = 'KAFKA',
value_format = 'JSON',
partitions = 1
);
- ksqlDB는 여러가지 직렬화 포맷으로 topic 메시지를 읽고 쓸 수 있음
- 직렬화 포맷은 key, value 각각에 별도로 지정 가능, 만약 동일하다면
format으로 지정 가능
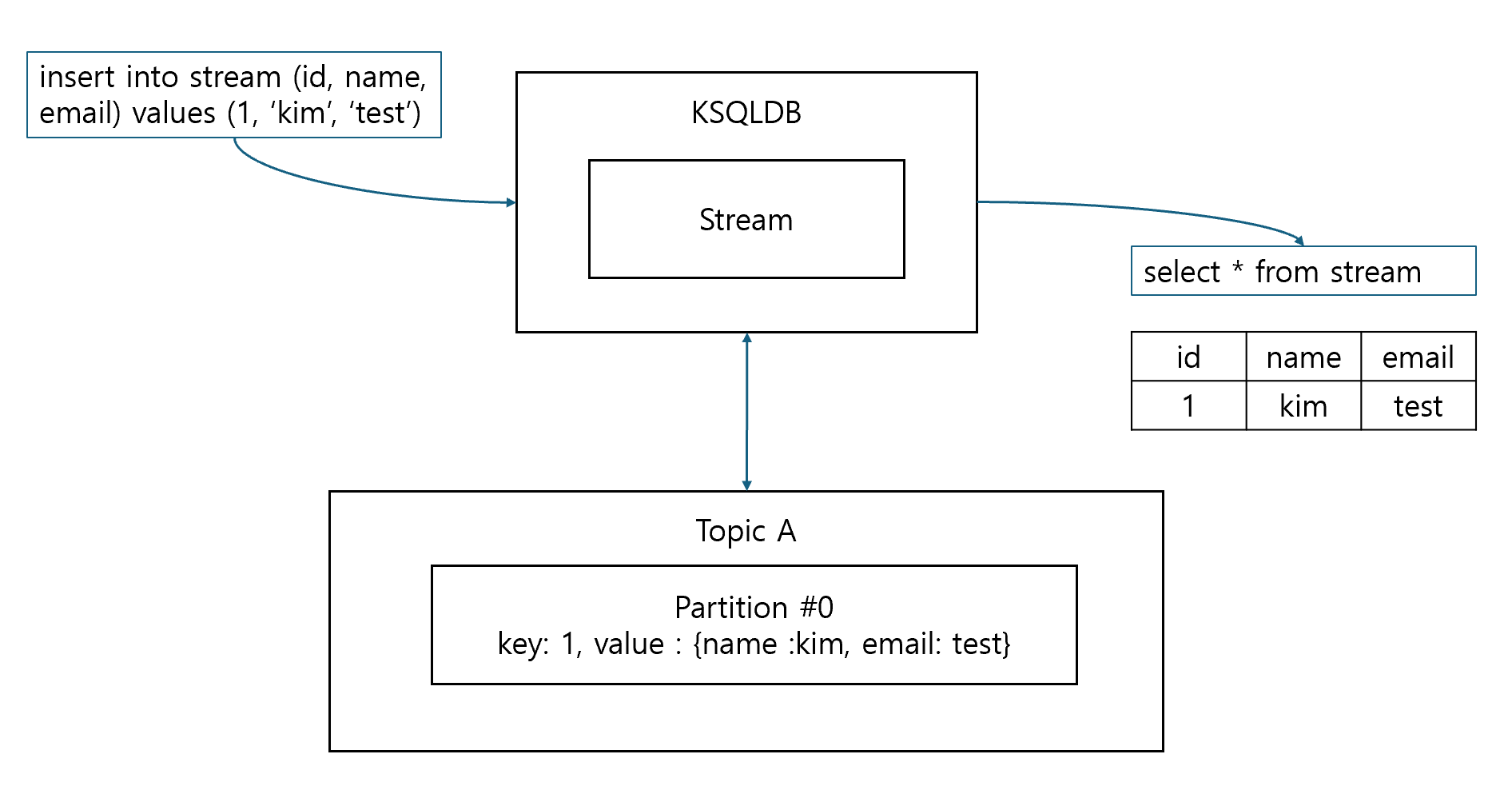
- 직렬화 포맷 유형
KAFKA: number(Integer, Float 등)과 String 등의 primitive 직렬화에 사용되며 보통 key 직렬화 포맷으로 사용JSON: json 포맷 직렬화AVRO: avro 포맷 직렬화. schema registry 사용 필요DELIMITED: csv 포맷 직렬화PROTOBUF: protocol buffer 형태 직렬화
Pull 쿼리와 Push 쿼리
Pull 쿼리
- 쿼리를 실행한 시점에, 쿼리 조건에 맞는 데이터를 KSQLDB에서 가져옴. 한번 수행 후 쿼리 종료됨
select * from stream;
Push 쿼리
- 쿼리 실행 이후 지속적으로 stream / table을 모니터링 하면서 쿼리 조건에 맞는 데이터가 추가 (변경) 되었을 때마다 데이터를 계속 가져옴
- 종료 시그널을 주지 않는 이상 쿼리가 종료되지 않음
select * from stream emit changes;
Pull 쿼리 제약
- stream에 group by 적용 시 pull 쿼리 수행 불가
- stream은 stateful한 처리 없이 append만 수행하여 데이터가 엄청 많은데 쿼리 날릴 때마다 group by (stateful)한 처리를 수행하면 성능 이슈 발생
- topic을 source로 하는 table에 pull 쿼리 수행 불가
- table이 source를 topic으로 하는 경우 mview가 아니므로 쿼리 수행 시점에 rocksdb 인스턴스가 새로 떠서 작업 처리함. 따라서 pull 쿼리와 같이 빈도가 잦은 쿼리는 rocksdb에 부담
- pull 쿼리는 수행 시 마다 새로운 consumer group과 consumer가 생성되고 종료됨
- push 쿼리는 쿼리가 유지되는 동안 계속 consumer group과 consumer가 유지됨
KSQL CLI
show topics;
set 'auto.offset.reset` = 'earliest';
print user_stream from beginning;
- 토픽 및 메시지 확인
describe user_stream extended; - stream / table의 DDL, 데이터 타입 등 주요 메타 정보 확인 가능
Query와 Consumer 동작
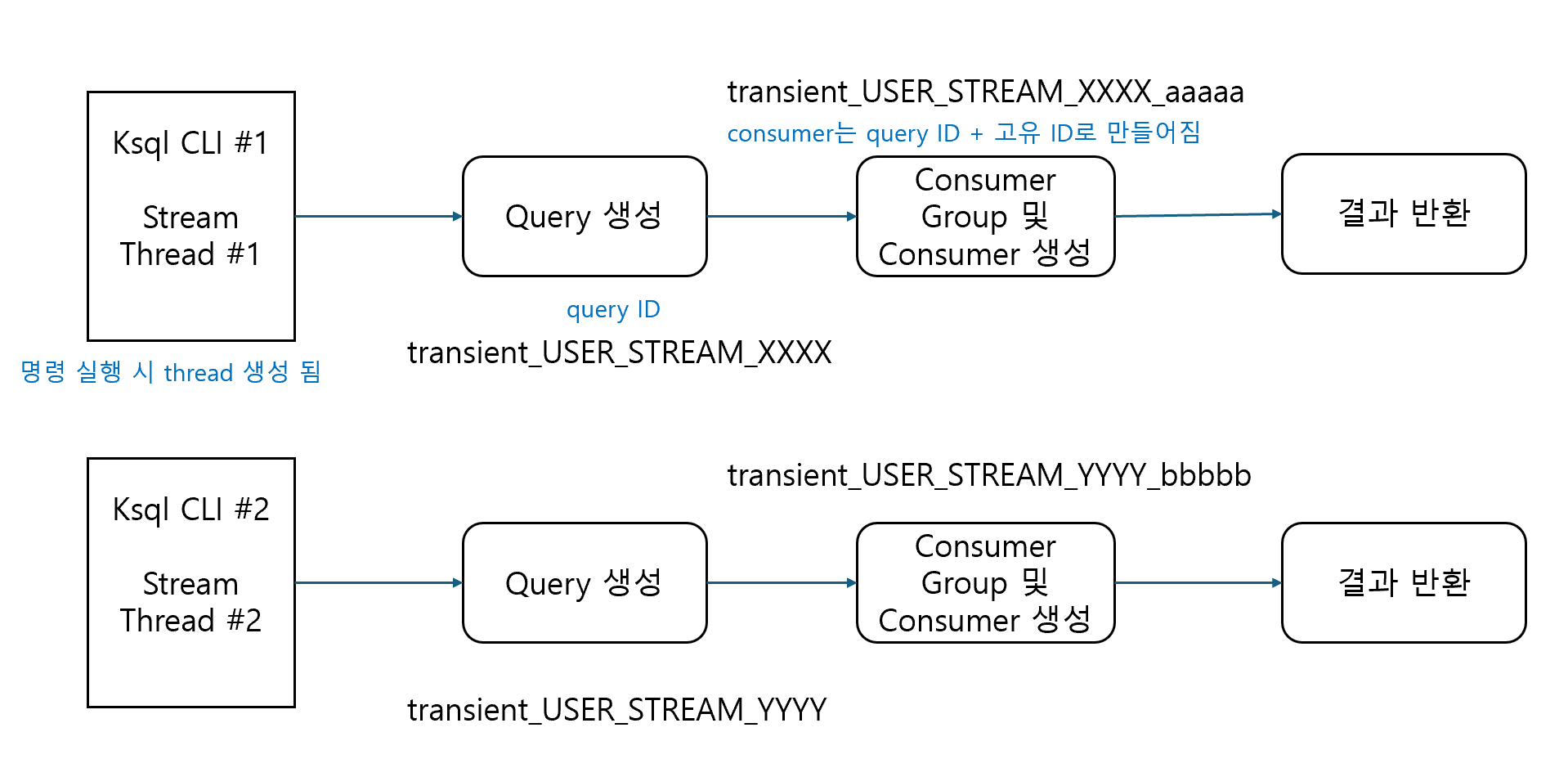
- 쿼리는 수행 상태를 가짐
- 동일한 쿼리더라도 select / insert로 수행되는 쿼리는 서로 다른 ID를 가짐
- mview에서 사용되는 CSAS, CTAS 쿼리는 동일한 쿼리일 경우 동일한 ID를 가짐
Pull 쿼리와 Push 쿼리 활용도
- pull 쿼리는 ksql CLI나 application에서 최종 데이터 추출하는데 사용
- push 쿼리는 materialized view에 변경된 데이터를 반영하는 데 주로 사용 (CLI 기반 조회도 가능)
ALTER DDL
- ksqlDB는 컬럼의 변경, 삭제를 허용하지 않고 오직 컬럼의 추가만 허용
- ksqlDB의 컬럼은 무조건 nullable이며 not null 제약 조건 부여 불가하지만 table의 경우 primary key에 대해서는 not null 묵시적 적용
alter stream user_stream add column phone varchar;
Table 생성하기
create table user_table
(
id int primary key,
name varchar,
email varchar
) with
(
kafka_topic = 'user_table',
key_format = 'KAFKA',
value_format = 'JSON',
partitions = 1
);
Topic을 소스로 가지는 Table에서 RocksDB 메커니즘
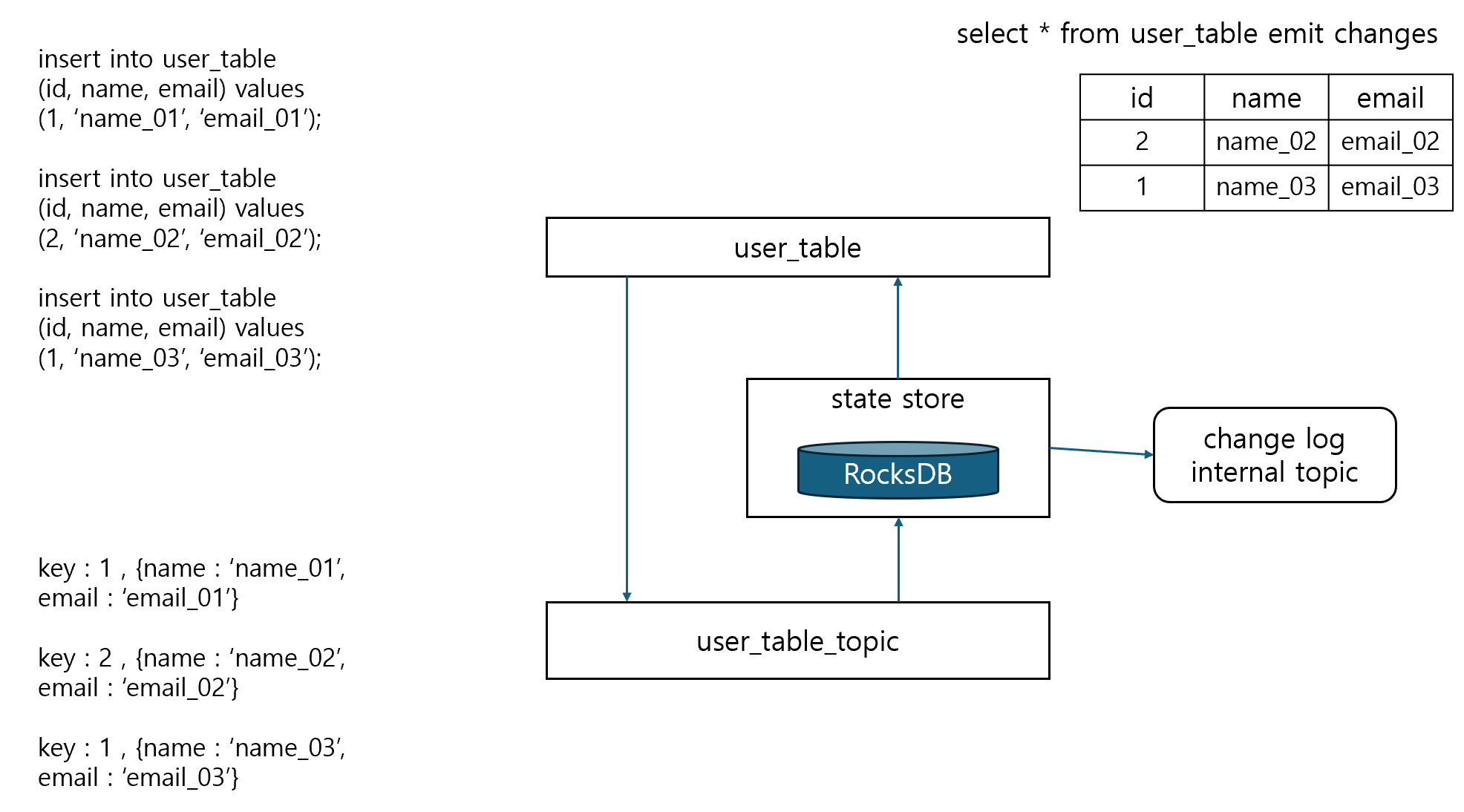
- push 쿼리 수행 시 rocksDB가 기동되어 stateful SQL 수행
- rocksDB instance는 쿼리 생성 시 생성되었다가 쿼리가 끝나면 종료됨
- change log는 push 쿼리 수행 중에 데이터 변경 사항을 내부 토픽으로 가지며 rocksDB의 복구 시 사용
- rocksDB의 기본 storage 디렉토리는
/tmp/kafka-streams이며ksql.streams.state.dir설정으로 변경 가능 - 쿼리 종료 시 change 내부 토픽 및 rocksDB 파일 모두 삭제됨
DATE / TIME / TIMESTAMP 타입 설명
DATE: 시분초를 제외한 월일년만 가지는 temporal 타입 (2023-02-01)TIME: 월일년을 제외한 시분초만 가지는 temporal 타입 (11:59:59)TIMESTAMP: 월일년 시분초, 밀리세컨드까지 가지는 temporal 타입 (2023-02-01 11:59:59.010)Time Units: temporal 관련 함수나 windows 절에서 사용되는 time unit- DAYS / HOURS / MINUTES / SECONDS / MILLISECONDS 등
- RDBMS와 달리 datetime은 없음
문자열 변환 함수
- temporal 타입을 문자열로 변경할 때는 FORMAT_XXX() 함수를, 문자열을 temporal 타입으로 변경할 떄는 PARSE_XXX() 함수를 사용
- temporal에서 문자열 변환
- FORMAT_DATE(Date, ‘yyyy-MM-dd’)
- FORMAT_TIME(Time, ‘HH:mm:ss’)
- FORMAT_TIMESTAMP(Timestamp, ‘yyyy-MM-dd HH:mm:ss’)
- 문자열에서 temporal 변환
- PARSE_DATE(‘2023-02-01’, ‘yyyy-MM-dd’)
- PARSE_TIME(‘11:59:59’, ‘HH:mm:ss’)
- PARSE_TIMESTAMP(‘2023-02-01 11:59:59’, ‘yyyy-MM-dd HH:mm:ss’)
Unix epoch 일자 / Milliseconds 값 변환
- Date / Timestamp 값을 int / big int 형 unix epoch 일자 / Milliseconds 값으로 변환할 경우 UNIX_XXX() 함수를 사용
- int / big int 형 unix epoch 일자 / Milliseconds 값을 Date / Time 값으로 변환할 때는 FROM_XXX() 사용
- unix epoch 일자 / milliseconds 값으로 변환
- UNIX_DATE(Date)
- UNIX_TIMESTAMP(Timestamp)
- Date / Timestamp 값으로 변환
- FROM_DAYS(unix epoch 일자)
- FROM_UNIXTIME(unix epoch milliseconds)
더하기 / 빼기 연산
- temporal 값에 일정 time unit을 더하고 빼기 위해서 DATEADD() 등의 함수가 지원됨
- time unit : DAYS / HOURS / MINUTES / SECONDS / MILLISECONDS
- DATEADD(time units, 기간, Date 컬럼명)과 같이 사용될 수 있으며 DATEADD는 DAYS만 사용 가능
- 더하기
- DATEADD(DAYS, 7, Date)
- TIMEADD(HOURS, 7 Time)
- TIMESTAMPADD(MINUTES, 10, Timestamp)
- 빼기
- DATESUB(DAYS, 7, Date)
- TIMESUB(HOURS, 7 Time)
- TIMESTAMPSUB(MINUTES, 10, Timestamp)