Kafka Connect 개요
Kafka Connect 개요
- Kafka 메시지 시스템 (Broker/Producer/Consumer)를 기반으로 다양한 데이터 소스 시스템 (ex: RDBMS)에서 발생한 데이터 이벤트를 다른 데이터 타겟 시스템으로
- 별도의 client 코딩 없이 seamless하게 실시간 전달하기 위해 만들어진 kafka component’
Kafka Connect 활용
- Data Pipeline
- DW ETL 활용
- Micro Service
- DB offloading
Kafka Connect 주요 구성요소
- Connector
- JDBC Source / Sink
- Debezium CDC Source
- Elasticsearch Sink
- File Connector
- MongoDB Source / Sink
- Transformation
- SMT
- Converter
- JsonConverter
- AvroConverter

Connect Cluster 아키텍처
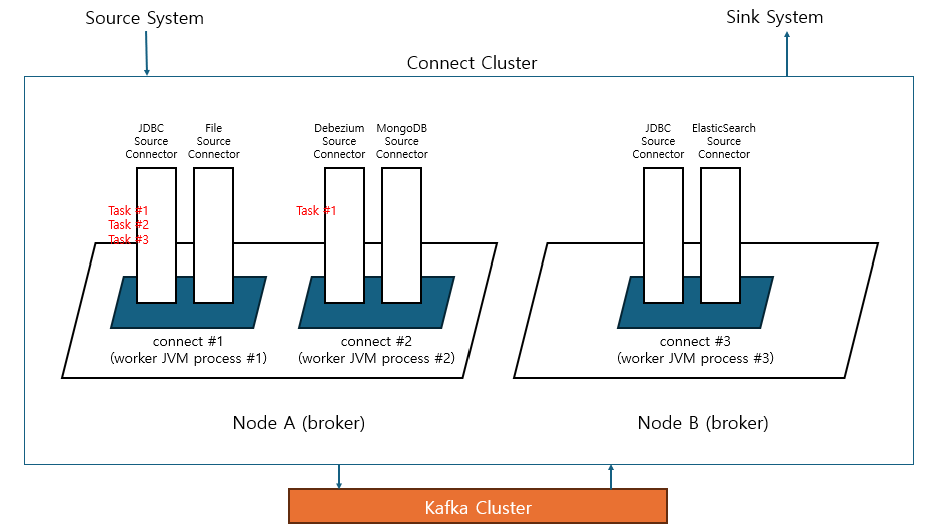
- connect cluster는 동일 group id를 지정하는 것으로 클러스터를 구축하고 kafka cluster 내의 internal topic들을 통해 서로의 상태 정보를 공유함
Connect, Connector, Worker, Task 정의
- connect는 connector를 기동시키기 위한 framework를 갖춘 JVM process 모델
- connect process를
worker process로 지칭함 - connect는 서로 다른 여러 개의 connector instance를 자신의 framework 내부로 로딩하고 호출 및 수행 가능
- connector instance 실제 수행은 thread 레벨로 수행되며 이를
task라고 한다 - connector가 병렬 thread에서 수행이 가능한 경우 여러 개의 task thread들로 해당 connector 수행 가능
- connect는 connect cluster로 구성될 수 있으며, 1개의 노드에서 여러 개의 worker process 또는 여러 개의 노드에서 여러 개의 worker process 들로 connect cluster 구성 가능
- connect 유형은
standalone과distributed mode로 나뉨- standalone : 단일 worker cluster만 가능
- distributed mode : 여러 worker로 가능
Connector 설치
- connect 설정의
plugin.path에 connector 설치 - confluent-hub 사용
Spool Source Connector
- 특정 디렉토리에 위치한 csv, json 포맷 등의 파일들을 event message로 만들어서 kafka로 전송하는 source connector
- 해당 디렉토리를 주기적으로 모니터링 수행하면서 새로운 파일이 생성될 때마다 kafka로 메시지 전송
Kafka Connect에 새로운 Connector 생성 순서
- Connector를 다운로드 받음. Connector는 여러 개의 jaf file로 구성
- Connector를 plugin.path로 지정된 디렉토리에 별도의 서브 디렉토리를 만들어 jar file을 이동시켜야함
- Connect는 기동 시에 plugin.path로 지정된 디렉토리 밑의 서브 디렉토리들에 위치한 모든 jar 파일을 로딩함. 신규로 connector를 connect로 올릴 시에는 반드시 connect를 재기동해야 반영됨
- Connect는 Connector 명, Connector 클래스 명, Connector 고유 환경 설정 등을 REST API를 통해 Connect에 전달하여 새롭게 생성
- REST API 성공 response와 별개로 connect log 메시지를 반드시 확인해야 함
Connector 로딩 확인
curl -X GET -H "Content-Type : application/json" http://localhost:8083/connector-plugins
spooldir_source.json
{
"name" : "csv_spooldir_source",
"config" : {
"tasks.max" : "3",
"connector.class" : "com.github.jcustenborder.kafka.connect.spooldir.SpoolDirCsvSourceConnector",
"input.path" : "/home/ubuntu/spool-test-dir",
"input.file.pattern" : "/\.*\\.csv",
"error.path" : "/home/ubuntu/spooldir-test-dir/error",
"finished.path" : "/home/ubuntu/spooldir-test-dir/finished",
"empty.poll.wait.ms" : 30000, # 모니터링 주기
"halt.on.error" : "false", # 파싱 오류 시 중지 여부
"topic" : "spooldir-topic",
"csv.first.row.as.header" : "true",
"schema.generation.enabled" : "true"
}
}
Spool Dir Source Connector 생성
curl -X POST -H "Content-Type : application/json" http://localhost:8083/connectors --data @spooldir_source.json
Connector Status 확인
curl -X GET http://localhost:8083/connectors
curl -X GET http://localhost:8083/connectors/csv_spooldir_source/status | jq '.'
Connector 수행 Thread 및 Task Thread 모니터링
ps -ef | grep java
jstack pid
Source Connect에서 Connector 등록 시 수행 프로세스

tasks.max개수만큼 thread 생성- connector 별 멀티 thread 지원 여부 다름
REST API 기반의 Connect 관리
- GET : 기동 중인 모든 connector 들의 리스트, 개별 connector의 config와 현재 상태
- POST : connector 생성 등록, 개별 connector 재기동
- PUT : connector 일시 정지 및 재시작, connector의 새로운 config 등록, config validation
- DELETE : connector 삭제
httpie 이용 REST API 호출
- httpie 설치
sudo apt-get install httpie
- connector 리스트 확인
http GET http://localhost:8083/connectors
- connector 등록하기
http POST http://localhost:8083/connectors @spooldir_source.json
- connector 삭제
http DELETE http://localhost:8083/connectors/csv_spooldir_source
- connector 일시 중지
http PUT http://localhost:8083/connectors/csv_spooldir_source/pause
- connector 재시작
http PUT http://localhost:8083/connectors/csv_spooldir_source/resume
전송 데이터의 스키마 필요성
- csv 문자열을 콤마 기준으로 파싱한 후, DB insert SQL을 만들기 위해서 파싱한 값을 타입에 따라 변환 해야 함
- consumer 입장에서 타입을 알 수 있는 방법은?
- 문자열 자체를 Serialization 해서 전송하지 않고 custom 객체를 생성해서 이를 직렬화해서 전송
public class OrderModel implements Serializable{
public String orderId;
public String shopId;
...
public LocalDateTime orderTime;
}
- custom 자바 객체를 이용하여 schema가 있는 정보 전송 시 문제
- custom 자바 객체를 customer에서 타겟 DB에 맞춰 매번 생성하기 어려움
- connector에서 schema 설정 시 파싱 후 객체 생성 필요 없이 schema 정보 포함 직렬화
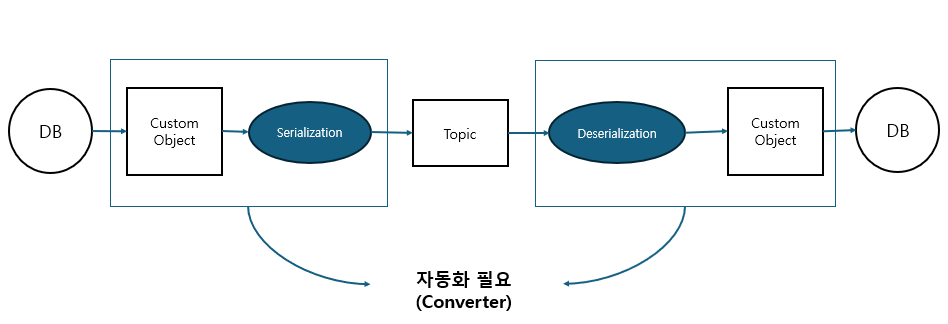
Converter 지원 포맷
- Json, Avro, Protobuf, String, ByteArray
{ "schema" : {"type" : "struct", "fields" : [{..},{..}], "optional" : false, "name" : ...}, "payload" : { ... } }
Converter의 Json Schema
- connect의 기본 설정은 json schema 설정
- converter 설정은 key, value 각각 해주어야 함
- (key or value).converter.schemas.enable = true 이면 schema 정보를 json 형태로 embedding하여 생성
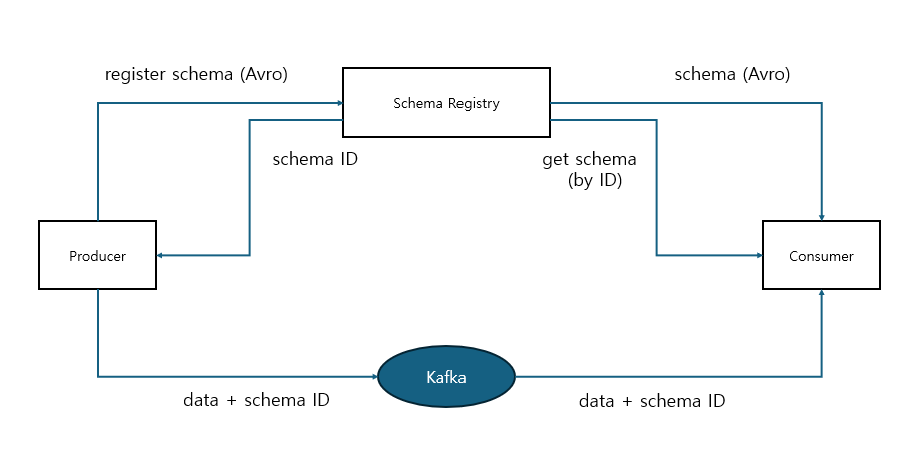
Schema Registry를 이용한 Schema 정보 중복 전송 제거
- confluent kafka는 schema registry를 통해 schema 정보 별도로 관리하는 기능 제공
- 토픽으로 전송되는 data의 schema는 schema registry에서 ID + version 별로 중앙 관리되므로 레코드 별로 schema를 중복해서 전송할 필요 없음
Connect 내부 정보 Topic 들
- connector의 메시지 처리 offset 및 connector 별 config와 상태 정보를 내부 토픽에 저장
- connect-offsets
- source connector 별로 메시지를 전송한 offset 정보 저장
- 한 번 전송한 메시지를 중복 전송 하지 않기 위함
- 기본 25개의 partition으로 구성
- connect-configs
- connector의 config 정보를 가짐
- connect 재기동 시 설정된 connector를 기동
- connect-status
- connector의 상태 정보를 가짐
- connect 재기동 시 설정된 connector를 기동
- __consumer_offsets
- consumer가 읽어들인 메시지의 offset 정보를 가짐
- 한 번 읽어들인 메시지를 중복해서 읽지 않기 위함
- 기본 50개의 partition으로 구성
kafka-console-consumer --bootstrap-server localhost:9092 --topic connect-offsets --from-beginning --property print.key=true | jq '.'
kafkacat / kcat 개요
sudo apt-get install kafkacat- 하나의 command로 producer, consumer 모두 사용
- 키 값을 보다 쉽게 출력
- 토픽 메시지의 포맷팅을 보다 다양하게 출력
- 메시지 헤더 정보 볼 수 있음
- 내부 offsets 값을 reset 하는데 주로 사용
kafkacat -b localhost:9092 -t 토픽명 -C -k#
kafkacat -b localhost:9092 -t 토픽명 -C -J -u -q | jq '.'
kafkacat -b localhost:9092 -L
-C: consumer-J: Json-u: unbuffered-q: verbosity 제거-L: 전체 토픽 메타 정보 확인
※ 내부 offsets rest 과정
1. connect-offsets 토픽에서 connect 별 key, partition 확인
kafkacat -b localhost:9092 -t connect-offsets -C -f `Key : %k, Value : %s, Partition : %p, Offset : %o '
2. 최종 offset 메시지가 있는 partition을 찾아서 NULL 적용
echo `["csv_spooldir_source", {"filename" : "spool..csv"}]#' | kafkacat -b loaclhost:9092 -t
connect-offsets -P -Z -k# -p 17
-P: producer-Z: null 가능-p: partition-k#: key 포함 (separator #)- echo로 ‘#’ separator 포함해서 파이프를 통해 producer로 전송, value는 NULL