JDBC Connector
JDBC Source Connector
- JDBC source connector는 RDBMS 별 JDBC driver가 별도로 설치되어야 함
- JDBC source connector는 JDBC driver를 이용하여 DB 접속 및 데이터 추출을 수행 후 producer를 이용하여 broker로 데이터를 전송함
- JDBC source connector는 source 시스템에 주기적으로 query를 날려 변경된 데이터를 추출하는 방식
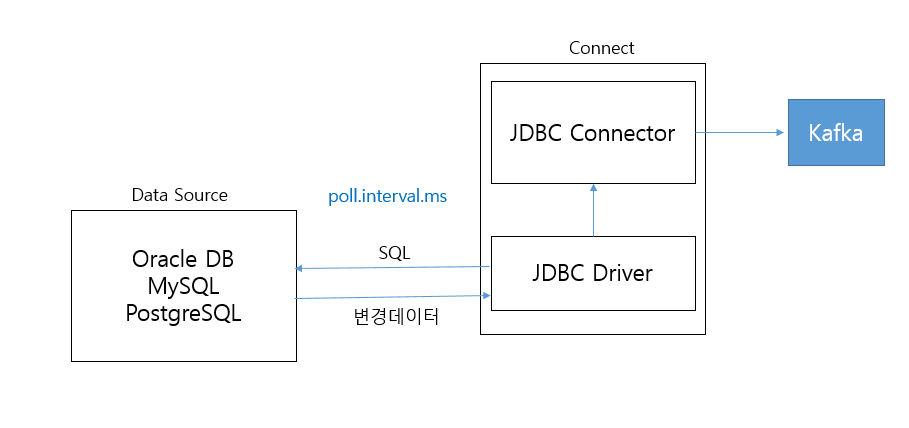
JDBC Source Connector 모드 유형
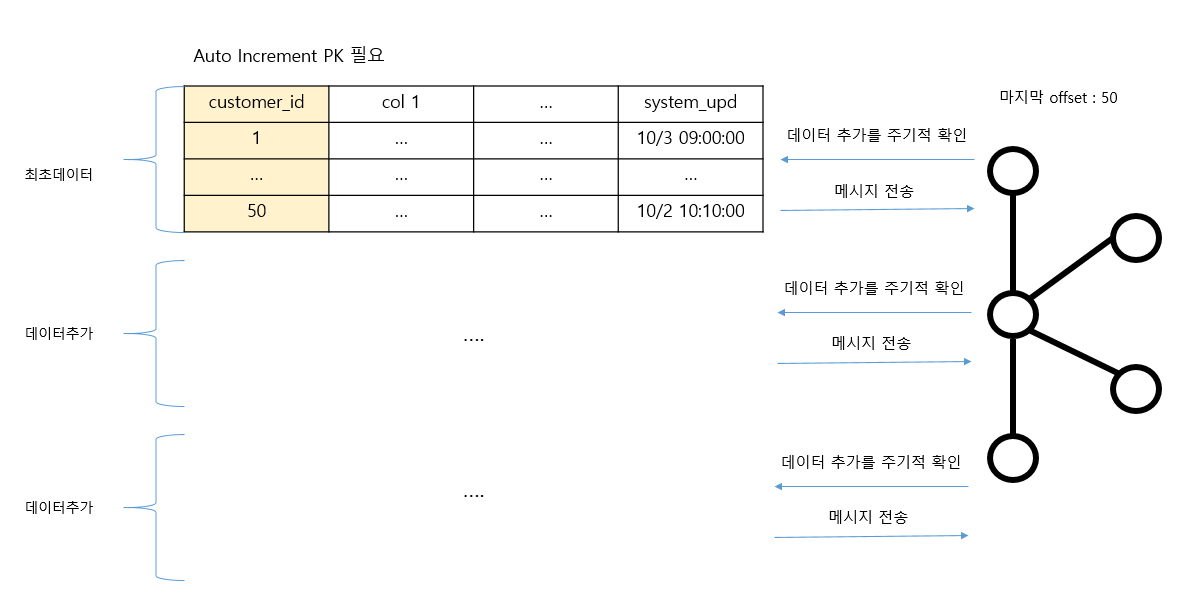
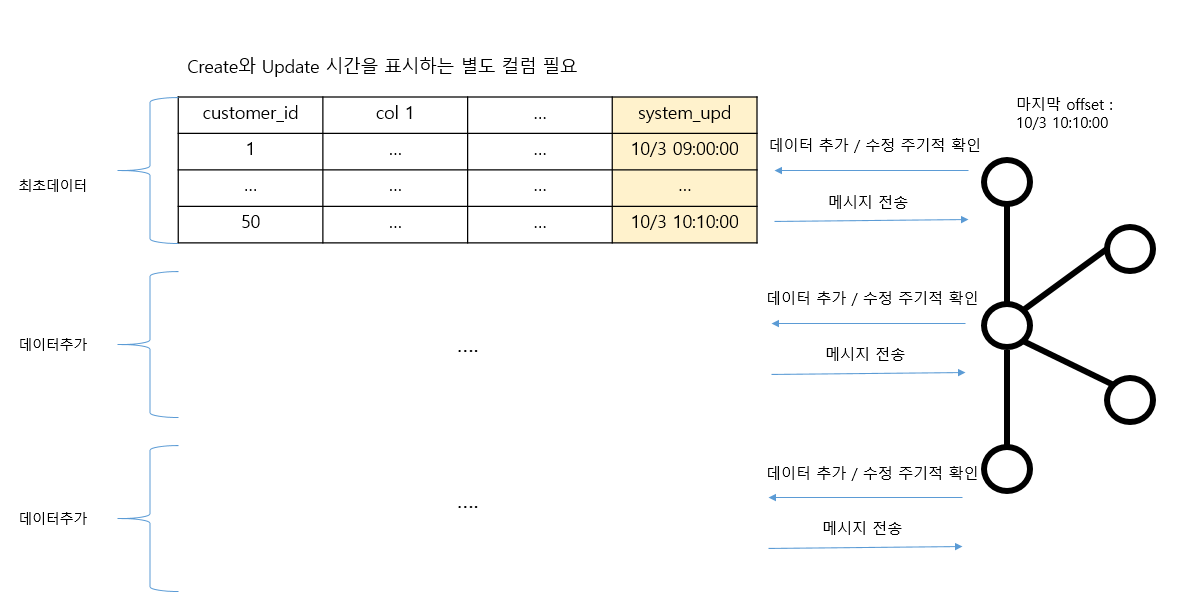
incremental query mode: 이전 데이터 추출 이후 새롭게 생성된 데이터나 업데이트 된 데이터를 kafka 전송. 모드 별로 대상 컬럼을 지정해 주어야 함incrementing: insert만 가능. auto incremental pk 컬럼 필요.timestamp: insert / update 가능timestamp + incrementing: insert / update 가능. 가장 안정적bulk: 테이블 데이터 한번에 모두 kafka 전송. 이후 테이블 데이터가 모두 삭제되어야 불필요한 재전송 안함
Incrementing 모드
Timestamp 모드
JDBC Source Connector 문제점
- source DB의 데이터 삭제 이벤트를 kafka로 전송 불가능
- CDC 기반 connector보다 source DB 성능에 상대적으로 더 큰 영향을 미칠 수 있음
- source 데이터의 모든 변경 이벤트가 제대로 kafka로 전송되었다고 보장되기 어려움
JDBC Connector 환경 구성
- JDBC source / sink connector download
- Mysql JDBC driver download
- JDBC connector, Mysql jdbc driver를
plugin.path이동 - connect 재기동
- plugin 정상 등록 확인
http http://localhost:8083/connector-plugins
Mysql 설치 및 환경 구성
sudo apt-get update && sudo apt-get upgrade
sudo apt-get install mysql-server mysql-client
sudo ufw allow mysql
mysql 접속하여 root password 변경
sudo mysql
create user 'root'@'%' identified with mysql_native_password by 'root';
grant all privileges on *.* to 'root'@'%' with grant option;
flush privileges;
mysql_native_password: 암호화된 연결 플러그인
시스템 기동 시 mysql 함께 기동
sudo systemctl enable mysql
DB 생성
sudo mysql -u root -p
create database om;
show databases;
새로운 사용자 추가 및 DB 사용 권한 할당
create user 'connect_dev'@'%' identified by 'connect_dev';
grant all privillegs on om.* to 'connect_dev'@'%' with grant option;
테이블 생성
mysql -u connect_dev -p
use om;
CREATE TABLE customers(
customer_id int NOT NULL AUTO_INCREMENT PRIMARY_KEY,
email varchar(255) NOT NULL,
name varchar(255) NOT NULL,
system_upd timestamp NOT NULL)
ENGINE=InnoDB;
create index idx_customers on customers(system_upd);
- update 용 system_upd 칼럼에 인덱스 생성
한국 표준시를 mysqld 환경에 적용
cd /etc/mysql/mysql.conf.d
sudo vi mysqld.cnf
default_timze_zon=`09:00`
mysql 재기동
sudo systemctl restart mysql
timezone 확인
show variables like `%time_zone%`;
Incrementing mode 용 JDBC Source Connector 생성 및 등록
{
"name" : "mysql_jdbc_on_source", // connector 명
"config" : {
"connector.class" : "io.confluent.connect.jdbc.Jdbc.SourceConnector", // connector class 명
"tasks.max" : "1",
"connection.url": "jdbc:mysql://localhost:3306/om",
"connection.user" : "connect_dev",
"connection.password" : "connect_dev",
"topic.prefix" : "mysql_om_", // topic 명은 topic.prefix + table 명으로 생성
"topic.creation.enable" : "true", // 지정된 topic 명의 topic 없을 경우 자동 생성
"topic.creation.default.replication.factor" : 1,
"topic.creation.default.partitions" : 1,
"catalog.pattern" : "om", // postgres, oracle 경우에는 schema.pattern
"table.whitelist" : "om.customers", // 여러 개의 경우 콤마로 분리
"poll.interval.ms" : 10000, // 조회 주기
"incrementing.column.name" : "customer_id", // mode가 incrementing일 경우 PK 컬럼
"mode" : "incrementing" // incrementing, timestamp, timestamp + incrementing
}
}
catalog.pattern: 지정된 스키마에 소속된 모든 테이블 연동- 여러 개 테이블 지정 시 개별 테이블 별 서로 다른 환경 설정을 적용할 수 없음
timestamp mode
"mode" : "timestamp",
"timestamp.column.name" : "system_upd"
timestamp + incrementing mode
"mode" : "timestamp + incrementing",
"timestamp.column.name" : "system_upd",
"incrementing.column.name" : "customer_id",
Schema를 가지는 JDBC Source Connector 생성 메시지
생성 메시지 포맷
{
"topic" : ...,
"partition" : ...,
"offset" : ...,
"tstype" : ...,
"ts" : ...,
"key" : null,
"payload" : '{"schema" : {"type" : ... , "fields" : ... ,
"optional": ... , "name" : ...},
"payload" : {...}}'
}
- 기본적으로 토픽에 저장되는 key 값은 자동 입력되지 않음 -> SMT를 이용하여 key 값 설정해야 함
- 컬럼 추가 / 삭제 / 타입 변경 등에 대응하기 위해 개별 레코드마다 자신의 schema (컬럼 타입, 컬럼 명 등)의 정보를 별도로 가지고 있으며 이를 메시지로 생성함
- schema 정보를 source connector에서 생성하지 않을 수 있지만 그럴 경우 sink connector에서 DB로 데이터 입력이 불가능
- 하나의 메시지는 개별 레코드의 schema 정보와 실제 값 payload로 구성됨
- schema 정보로 인하여 개별 레코드에 대한 토픽 메시지 크기가 매우 커짐
Topic 메시지 전송 시 Schema 출력 끄기
"key.converter.schemas.enable" : "false",
"value.converter.schemas.enable" : "false"
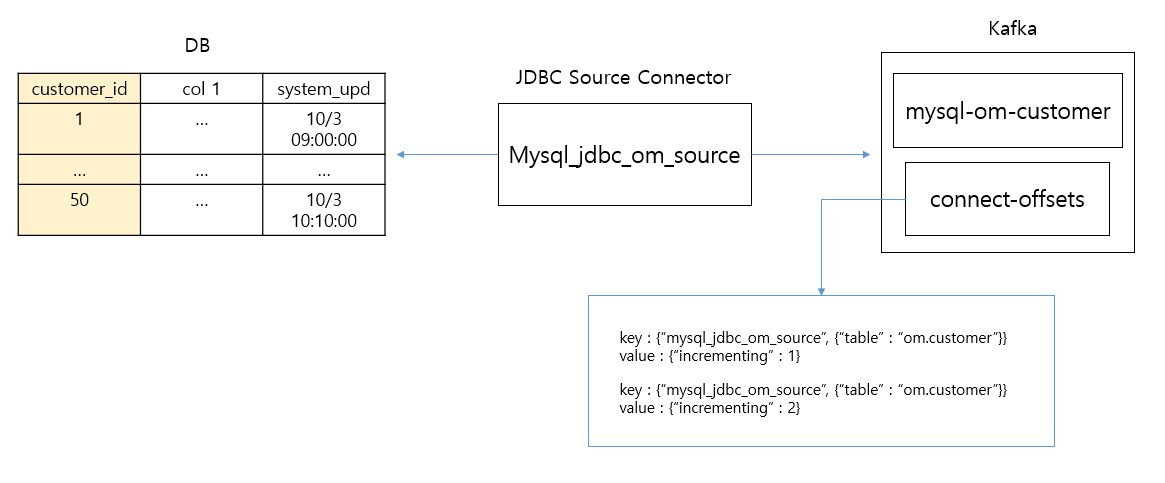
JDBC Source Connector의 offset 메커니즘
incrementing
timestamp
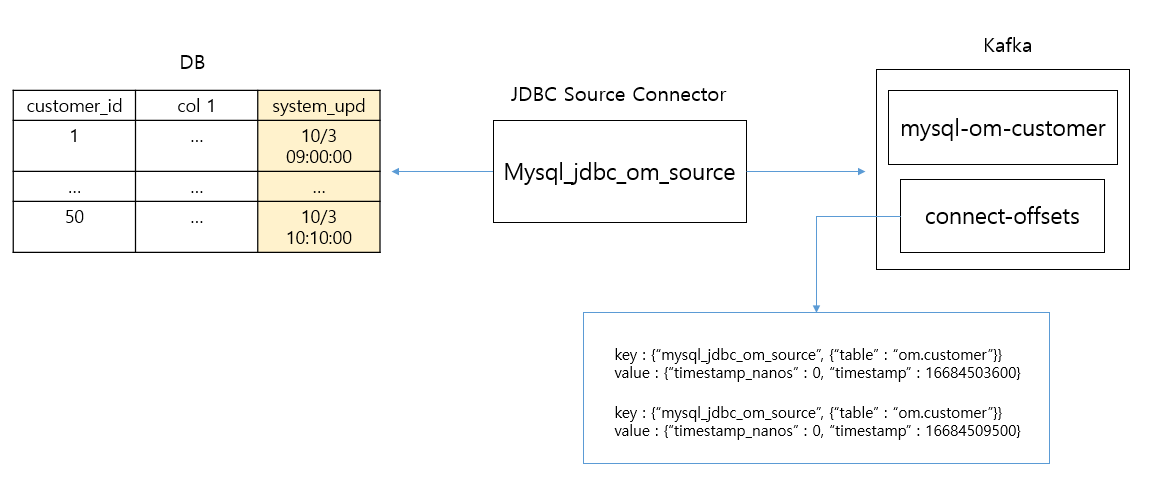
connect-offsets topic 삭제로 reset 하기
- 기존 connector 삭제
- connect 내리기
- source connector topic 삭제
- connect-offsets, connect-configs, connect-status topic 삭제
- connect 재가동
SMT (Single Message Transform)
- SMT를 이용하여 테이블의 PK를 key값으로 설정 가능
- ValueToKey는 value에서 메시지 key 값을 변환
- ExtractField는 메시지에서 특정 필드만 추출
{
"name" : "mysql_jdbc_om_source",
"config" : {
"connector.class" : "io.confluent.connect.jdbc.JdbcSourceConnector",
...
"transforms" : "create_key, extract_key",
"transforms.create_key.type" : "org.apache.kafka.connect.transforms.ValueToKey",
"transforms.create_key.fields" : "customer_id",
"transforms.extract_key.type" : "org.apache.kafka.connect.transforms.ExtractField$KEY",
"transforms.extract_key.field" : "customer_id"
}
}
ValueToKey
{
...
"key" : {
"schema": {
"type": "struct",
"fields": [
{
"type": "int32",
"optional": "false",
"field": "customer_id"
}
],
"optional": "false"
},
"payload": {
"customer": 3
}
},
"payload" : ...
...
}
- ValueToKey 적용 시 value에서 지정한 fields에 대해 struct type으로 key 추출함
ValueToKey + ExtractField
{
...
"key" : {
"schema": {
"type": "int32",
"optional": "false"
},
"payload": 3
},
"payload" : ...
...
}
- ExtractField 적용 시 key의 type이 단일 type이 되며 payload가 컬럼 값으로 적용됨
여러 개의 컬럼으로 구성된 PK를 Key 값으로 설정
{
"name" : "mysql_jdbc_om_source",
"config" : {
"connector.class" : "io.confluent.connect.jdbc.JdbcSourceConnector",
...
"transforms" : "create_key",
"transforms.create_key.type" : "org.apache.kafka.connect.transforms.ValueToKey",
"transforms.create_key.fields" : "customer_id, order_id",
"mode" : "timestamp",
"timestamp.column.name" : "system_upd"
}
}
- ValueToKey에 pk가 되는 컬럼명들을 fields로 적용
- ExtractField는 적용하지 말아야 함
- 일반적으로 incrementing mode로 설정이 어려움. timestamp mode 설정 필요
topic 명 변경
- SMT에서 정규 표현식을 사용하여 topic 명 변경
- 주요 속성
regex: topic 명 매칭을 위한 정규 표현식replacement: 매칭된 표현식에 대체될 문자열
{
"name" : "mysql_jdbc_om_source",
"config" : {
"connector.class" : "io.confluent.connect.jdbc.JdbcSourceConnector",
...
"topic.prefix" : "mysql_om_smt_key_",
"table.whitelist" : "om.customers",
"transforms" : "create_key, extract_key, rename_topic",
"transforms.rename_topic.type" : "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.rename_topic.regex" : "mysql_on_smt_key_(.*)",
"transforms.rename_topic.replacement" : "mysql_$1",
"transforms.create_key.type" : "org.apache.kafka.connect.transforms.ValueToKey",
"transforms.create_key.fields" : "customer_id",
"transforms.extract_key.type" : "org.apache.kafka.connect.transforms.ExtractField$KEY",
"transforms.extract_key.field" : "customer_id"
}
}
- 정규 표현식
.: 임의 단일 문자*: 0번 이상 반복 가능.*는 임의의 문자열을 의미하지만(.*)으로 그룹핑하면 매칭 결과를 반환 가능. 이를 replacement의$1에서 받아서 적용
JDBC Sink Connector
- 카프카 토픽에서 메시지를 읽어들여서 타겟 DB로 데이터 입력 / 수정 / 삭제를 수행
- connect의 consumer가 주기적으로 카프카 토픽 메시지를 읽어서 타겟 DB로 데이터 연동
- RDBMS에서 데이터 추출은 JDBC source connector, CDC source connector 등을 사용하지만 RDBMS로 데이터 입력은 주로 JDBC sink connector를 사용
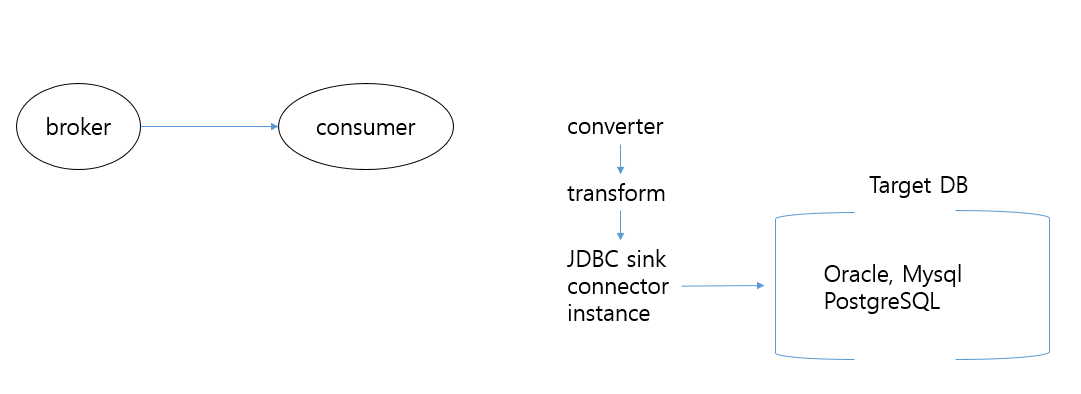
환경 구성
create database om_sink;
grant all privileges on om_sink.* to 'connect_dev'@'%' with grant option;
use om_sink;
create table customer_sink(
customer_id int NOT NULL AUTO INCREMENT PRIMARY KEY,
email varchar(255) NOT NULL,
name varchar(255) NOT NULL,
system_upd timestamp NOT NULL) ENGINE=InnoDB;
JDBC Sink Connector Config
{
"name" : "mysql_jdbc_sink",
"config" : {
"connector.class" : "io.confluent.connect.jdbc.JdbcSinkConnector",
"tasks.max" : "1",
"topics" : "mysql_jdbc_customers",
"connection.url" : "jdbc:mysql://localhost:3306/om_sink",
"connection.user" : "connect_dev",
"connection.password" : "connect_dev",
"insert.mode" : "upsert", // upsert는 insert+update
"pk.mode" : "record_key", // pk가 key에 있음. record_value는 pk가 value에 있음
"pk.fields" : "customer_id", // pk 컬럼명 (테이블의 컬럼)
"delete.enabled" : "true", // value가 NULL인 경우 데이터 삭제 여부. pk mode는 record_key여야 함
"table.name.format" : "om_sink.customers_sink", // 입력 테이블 명, 없으면 topic 명으로 생성됨
"auto.create" : "true", // 테이블 자동 생성. 컬럼 타입이 멋대로 만들어지므로 비권장
"auto.evolve" : "true", // 소스 테이블 변경 사항 자동 반영 여부
"key.converter" : "org.apache.kafka.connect.json.JsonConverter",
"value.converter" : "org.apache.kafka.connect.json.JsonConverter"
}
}
- pk 컬럼이 여러 개인 경우
pk.fields에 여러 개 지정 가능
JDBC Sink Connector의 성능 향상 방법
- topic의 partition 수를 늘리고 거기에 맞게
task.max증가 - task.max 수는 topic partition 수와 cpu core 수에 맞게 설정
- task.max를 증가시켜도 target 테이블에 인덱스가 많이 있는 경우는 수행 성능이 증가하지 않음
Source 테이블의 스키마 변경을 Sink 테이블에서 자동 반영
auto.evolve = true설정은 source 테이블의 스키마 변경을 JDBC sink connector가 자동으로 인지하여 sink 테이블에 반영- 하지만 스키마 변경 유형에 따라 제대로 반영이 되지 않는 경우가 있으므로 유의 필요
JDBC Sink Connector의 Update 로직
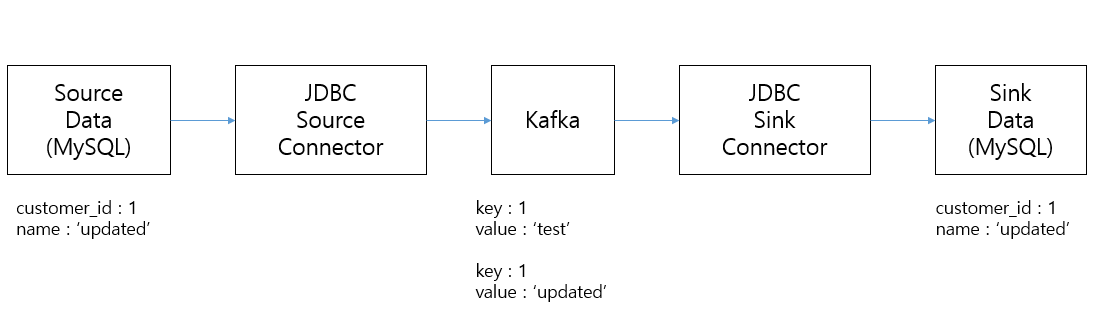
- sink에서 update를 캡처하려면 timestamp도 함께 갱신 필요
- sink에서 update로 kafka 메시지 event 발생
- sink connector는 target 테이블의 해당 pk로 기존 레코드가 있으면 update 적용
- incrementing인 경우는 같은 key로 토픽에 데이터가 생성되지 않으므로 update 불가능
JDBC Sink Connector의 Delete 로직
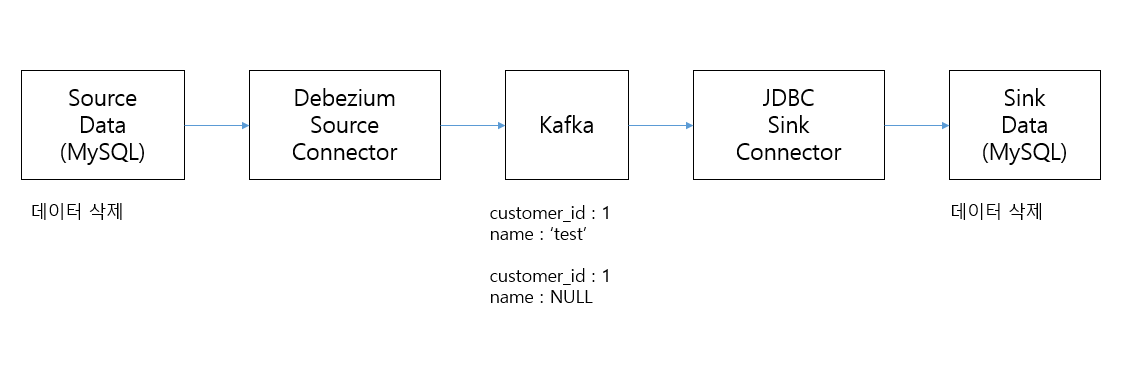
- debezium cdc source connector는 delete도 kafka에 이벤트로 발생시키며 key 값은 pk, value는 null 값으로 발생
- sink connector는 해당 pk로 기존 레코드가 있는 경우 delete 적용
Upsert 기반의 JDBC Batch 처리
- connector 설정인
insert.mode = upsert이면 insert 시와 update 시 모두 동일하게 upsertSQL이 수행됨insert into 테이블 명 values (...) on duplicate key update ... ;
JDBC Source Connector의 날짜 / 시간 데이터 변환

create table datetime_tab(
id int NOT NULL PRIMARY KEY,
order_date date NOT NULL,
order_datetime datetime NOT NULL,
order_timestamp timestamp NOT NULL,
system_upd timestamp NOT NULL)
ENGINE=InnoDB;
create table datetime_tab_sink(
id int NOT NULL PRIMARY KEY,
order_date date NOT NULL,
order_datetime datetime NOT NULL,
order_timestamp timestamp NOT NULL,
system_upd timestamp NOT NULL)
ENGINE=InnoDB;
- 정수형으로 전송된 시간 데이터를 JDBC sink connector가 알아서 포맷팅 수행 (yyyy-MM-dd HH:mm:ss)