Debezium CDC Connector
CDC (Change Data Capture) 개요
- CDC는 RDBMS오 NoSql 등의 data store 시스템의 변경 데이터를 기록하는 내부 트랜잭션 로그 파일로부터 변경 데이터를 capture하는 설계, sw를 지칭
- DB 내부 트랜잭션 로그 파일로부터 변경 데이터를 추출하므로 소스 DB 성능에 큰 영향 없이 대용량 변경 데이터를 매우 빠르게 추출하고 준실시간으로 타겟 DB 연동 가능
- DBMS 복제 수준의 안정적이고 정확한 데이터 추출 가능
- Debezium은 이러한 CDC 기반의 분산 플랫폼으로 기본적으로는 카프카 커넥터로 제공됨
- JDBC source connector의 경우 DB에 select 쿼리를 주기적으로 전송하고 변경 사항 추적은 특정 컬럼 (key, timestamp) 값에 대해 기존에 없던 새로운 값이 추가된 경우만 capture 가능
DB 복제 기반 CDC 솔루션
- 대부분의 CDC 솔루션은 DB 내의 트랜잭션 log를 이용하는 DB replication에 기반함
DBMS 별 트랜잭션 로그 파일
- Oracle : Redo log
- Mysql : Bin log
- PostgreSQL : WAL (Write-Ahead Log)
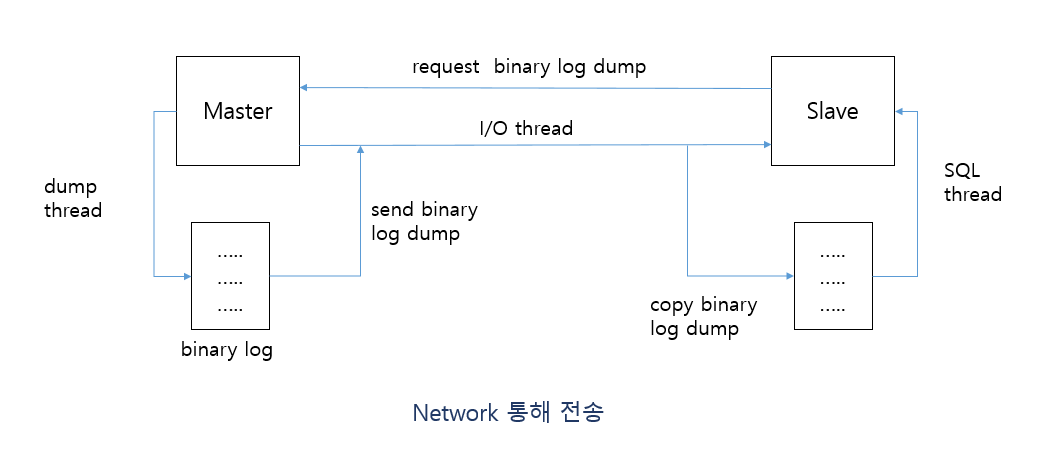
Mysql 복제 개요
- bin log 기반 구현
- master bin log를 slave로 전송하고, 전송된 bin log를 SQL로 적용
- 복제 cluster 내의 master와 slave DB는 고유의 server_id 설정 값을 가짐

Binary Log 데이터 포맷
- statement 방식 : 실행된 SQL을 기록. row 방식보다 처리속도가 느리고 덜 안정적
- row 방식 : 변경된 데이터를 기록. InnoDB binary log의 기본 데이터 포맷. 많은 데이터 변경 시 용량이 커질 수 있음
Row 포맷 유형
mysqld.cnf에서binlog_row_image설정- full : 변경이 발생한 레코드의 모든 컬럼의 변경 전 / 후 값을 bin log에 기록
- insert는 변경 후만 기록
- update는 변경 전 / 후 기록
- delete는 변경 전만 기록
- minimal : 변경이 적용되어 필요한 컬럼만 기록
- insert는 SQL에 명시된 컬럼 값만 기록
- update는 변경 전 pk와 SQL에 명시된 컬럼 값만 기록
- delete는 변경 전 pk만 기록
- noblob : full과 동일하지만 blob, text 컬럼의 변경 값은 기록하지 않음
Mysql 복제 환경 확인
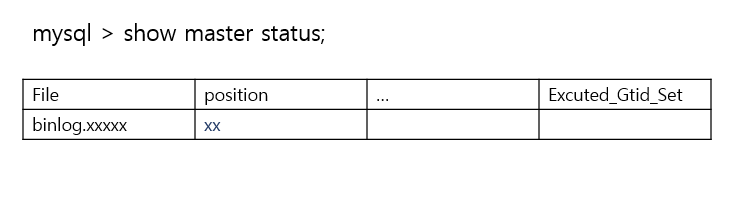
- position 정보가 있는지 확인
- binlog는 파일 위치 기반이 default
- mysql binlog 복제 방법
- 파일 위치 기반 복제 : DB 변경 사항을 binlog 파일 명과 파일 내 offset 조합 식별
- GTID 기반 복제 : 복제 cluster 구성 여러 DB 간에 소스 DB 변경 사항 이벤트를 동일 고유 식별자로 식별

- log_bin 값이
ON으로 되어있으면 됨 - 설정이 되어 있지 않은 경우
/etc/mysql/mysql.conf.d/mysql.conf에 설정 추가 후 재기동server_id = 223344 log_bin = binlog binlog_format = Row binlog_row_image = Full expire_logs_days = 0
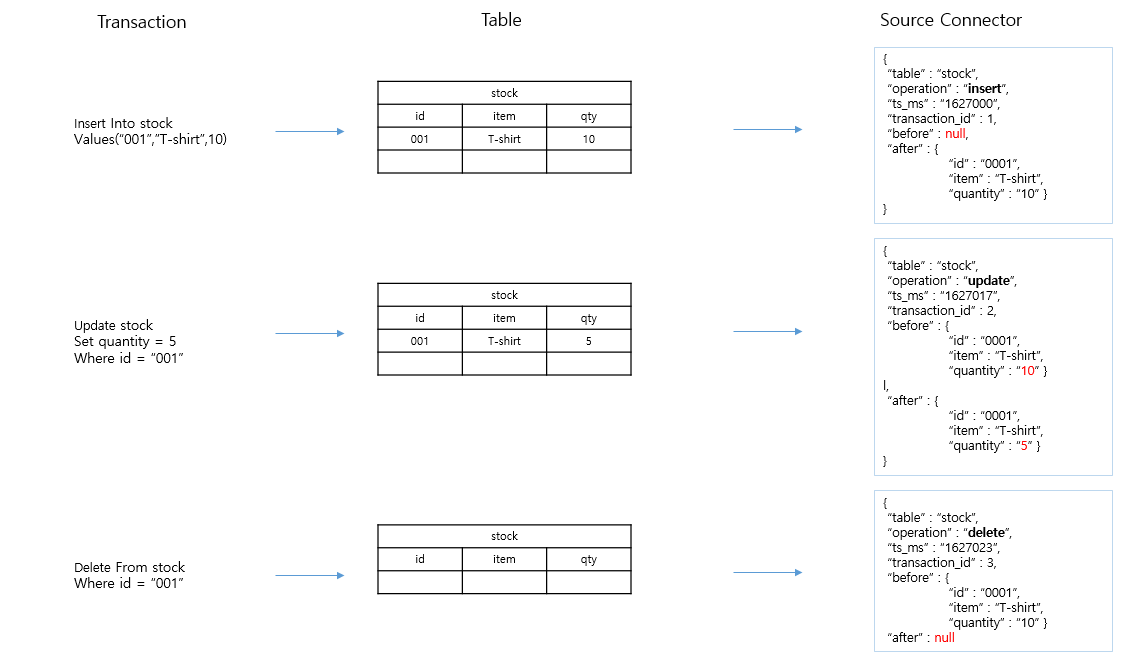
Debezium CDC Source Connector 이벤트 메시지
Kafka 연계 시 유의 사항
- debezium은 source connector만 지원하므로 sink는 JDBC sink connector로 수행
- 소스 DB의 DDL 변경을 타겟 DB에 정확히 반영 어려움
- 타겟 DB 데이터 입력이 JDBC sink connector의 기능에 제약
- 소스 데이터 truncate table, drop table 타겟 적용되지 않음
- v2.1에서 truncate 반영 예정
- debezium은 kafka로 메시지 전송까지만 담당하므로 기존의 사용 CDC 솔루션과 차이 존재
- 상용 솔루션은 타겟 DB에 복제까지 담당
Connector Parameter 특징
- 하나의 source connector로 여러 개의 source 테이블 데이터를 유연하게 추출 가능하며 하나의 source 테이블은 하나의 topic으로 생성
- source 테이블의 pk는 자동으로 kafka 토픽의 key 값으로 생성됨
- 토픽 명은 기본으로
{database server name}.{database 명}.{table 명}으로 생성되고, SMT를 통해 변경 가능 - source table DDL 변경을 kafka 토픽으로 저장 가능. topic 메시지는 JDBC source connector와 다르게 구성되어 있으며 (befor / after 구성) JDBC sink connector에서 데이터를 입력하기 위해서는 SMT를 이용하여 메시지 재변경 필요
- delete를 위한 tombstone 메시지 적용을 위해 SMT 적용
- data, datetime, timezone의 일자 / 시간 관련 타입, numeric, decimal 등의 precision / scale 관련 타입을 JDBC sink connector와 호환될 수 있는 타입으로 만들어져야 함
{
"name" : "mysql_cdc_oc_source",
"config" : {
"connector.class" : "io.debezium.connector.mysql.MysqlConnector",
"tasks.max" : "1",
"database.hostname" : "192.168.56.101",
"database.port" : "3306",
"database.password" : "connect_dev",
"database.allowPublickeyRetrieval" : "true",
"database.server.name" : "mysql01", // connector 명칭 해당 값 접두어로 토픽 명 생성
"database.include.list" : "oc",
"table.include.list" : "oc.customers.oc.orders",
"poll.interval.ms" : "1000",
"include.schema.changes" : "true", // source table DDL 변경 반영. 기본 true
"database.history.kafka.bootstrap.servers" : "192.168.56.101:9092",
"database.history.kafka.topic" : "schema_changes.mysql.oc",
"key.converter" : "org.apache.kafka.connect.json.JsonConverter",
"value.converter" : "org.apache.kafka.connect.json.JsonConverter",
"tombstones.on.delete" : "true", // delete 발생 시 tombstone 발생 여부. 기본 true
"transforms" : "unwrap",
"transforms.unwrap.type" : "io.debezium.transforms.ExtractNewRecordState", // after 메시지만 생성하기 위한 SMT
"transforms.unwrap.drop.tombstones" : "false", // after 메시지 생성 시 tombstone 메시지의 경우 삭제 여부
"time.precision.mode" : "connect", // 기본은 adaptive_time_microseconds. time 관련 단위 기본 레벨로 변경 (microseconds -> milliseconds)
"database.connectionTimeZone" : "Asia/Seoul"
}
}
- tomestone 데이터 발생 위해 sink connector에서도
delete.enabled도 true 이어야 함
Debezium Source Connector 생성 메시지 포맷
{
"schema" : {...}, // key 필드의 schema 정보
"payload" : {...}, // key 값
"schema" : {...}, // value 필드의 schema 정보
"payload" : {...} // value 값
}
- value 필드에서는 before과 after에 대한 schema 정보 및 값을 모두 가짐
Topic 명의 dot(.)을 dash(-)로 변경
- 토픽 명을 직접 지정해주지 않은 경우, debezium은 topic 명을 기본적으로
database.server.name + "." + database.include.list + "." + table.include.list를 조합해서 만듦"transforms" : "rename_topic", "transforms.rename_topic.type" : "org.apache.kafka.connect.transforms.RegexRouter", "transforms.rename_topic.regex" : "(.*)\\.(.*)\\.(.*)" "transforms.rename_topic.replacement" : "$1-$2-$3"
동일 Source Table에 여러 개의 Connector 사용 시 문제점
- 여러 개 connector를 동일 테이블에 적용은 가능하지만 이들 중 단 하나의 connector에만 topic 메시지가 생성됨
Snapshot 모드
- 스냅샷은 connector 생성 시점의 binlog와 binlog position, DB와 읽어들일 테이블의 schema (DDL), 대상 테이블의 초기 레코드를 읽어서 카프카에 저장 등의 작업 수행
connect-offsets에 해당 connector 명과 서버 명으로 offset 정보가 없을 때 수행snapshot.mode = initial로 default 설정 시 connector를 생성하기 이전에 소스 테이블에 생성되어 있는 레코드를 모두 카프카로 보내어서 동기화를 시킴- 오래된 테이블의 경우 초기 binlog 가 없어서 오류 발생할 수 있음
snapshot.mode = schema_only로 설정 시 connector 등록 후 변경 데이터만 메시지로 생성- 초기 데이터는 sink 테이블로 수동 마이그레이션 필요
Connector 최초 생성 시 수행 프로세스
- MySql DB에 Global read lock(DB 내 모든 테이블 lock)을 획득. 다른 client 들이 테이블에 write할 수 없음
- connector가 Global read lock 획득 권한이 없으면 Table Lock (개별 테이블 lock)을 획득함. 이 경우 테이블에 snapshot이 완료될 때까지 write 불가능
- connector가 Global read lock 획득 권한이 없으면 Table Lock (개별 테이블 lock)을 획득함. 이 경우 테이블에 snapshot이 완료될 때까지 write 불가능
- 현재 binlog의 position을 읽음
- connector가 읽어들일 테이블의 스키마 정보 가져옴
- Global read lock 해제 (다른 클라이언트가 테이블 write 가능)
- DDL 변경 사항을 schema change topic에 기록
- DDL 변경 사항을 schema change topic에 기록
- connector가 대상 테이블 들의 기존 레코드를 topic에 전송
- topic에 기록된 레코드 offset을
connect-offset토픽에 기록
오래된 binlog purge 시 connector 기동 이슈
- connector는 자신이 읽어서 kafka로 보낸 offset 정보를 binlog 명과 binlog position으로 connect-offsets 토픽에 기록
- 오랫 동안 connector를 기동하지 않는다면, binlog가 mysql expire log 기간 이상 저장될 경우 삭제될 수 있음
- connector는 connect-offsets에 기록된 binlog를 binlog 디렉토리에서 찾지 못해서 기동 불가
- 새롭게 connector를 생성하거나 connect-offsets 재설정 필요
Numeric과 Decimal Data Type
- precision(전체 자리 수)과 scale(소수점 이하 자리 수) 값을 가지는 숫자 data type
- Mysql은 Numeric과 Decimal이 동일한 타입임
- Decimal(7,3) 이면 9999.999 형태로 DB 저장
- Decimal(10,0) 이면 100.1을 입력해도 100으로 저장됨
- Decimal(10)은 precision 10, scale 0 임
- precision 또는 scale 설정하지 않으면 기본적으로 precision 10, scale 0
Numeric과 Decimal 데이터 타입 변환
- debezium default 설정인
decimal.handling.mode=precision일 때 numeric / decimal 모두 bytes 형태 변환 org.apache.kafka.connect.data.Decimal을 이용하여 변환되며 schema에 parameters로 scale과 precision 값 표현
컬럼명 : unit_price
타입 : Decimal(10,2)
rkqt : 100.00
// schema
{
"type" : "bytes",
"name" : "org.apache.kafka.connect.data.Decimal",
"parameters" : {
"scale" : "2",
"connect.decimal.precision" : "10"
},
"field" : "unit_price"
}
Mysql Temporal Type 변환 시 이슈
- date / time / datetime 타입 변환 시 debezium source connect의 변환 클래스 명을 JDBC sink connector가 인지하지 못하므로 오류 발생
- timestamp 타입은 문자열로 변환되며 소스 DB의 timezone에 관계 없이 UTC timezone으로 변경됨
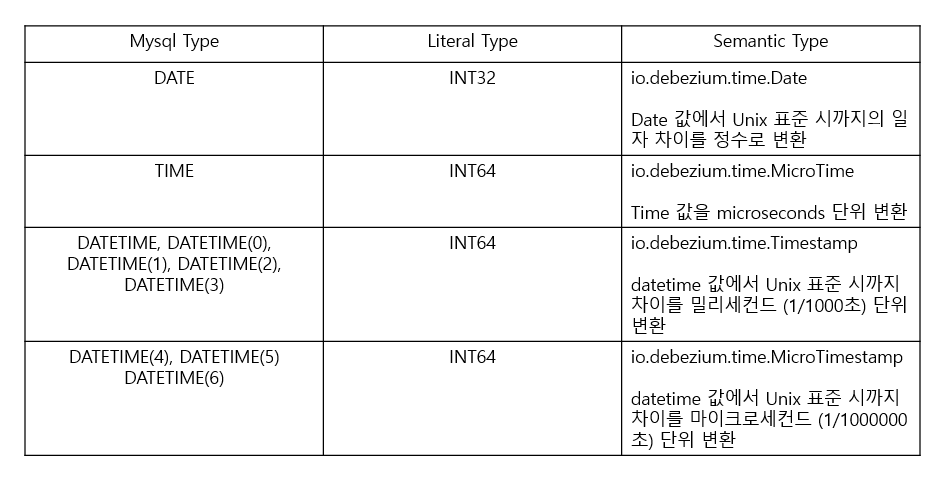
- debezium source connector는 date / time / datetime 변환 모드를 설정할 수 있는
time.precision.mode파라미터 제공 time.precision.mode = connect는 connect의 기본 변환 타입 (이것을 사용해야 함!)adaptive_time_microseconds설정 시 debezium 변환 클래스를 JDBC sink connector가 인지할 수 없음- adaptive_time_microseconds 설정 시에 microsecond 단위로 변환된 unix epoch time으로 millisecond 단위 변환을 처리하는 JDBC sink connector 오류 발생
adaptive_time_microseconds
connect
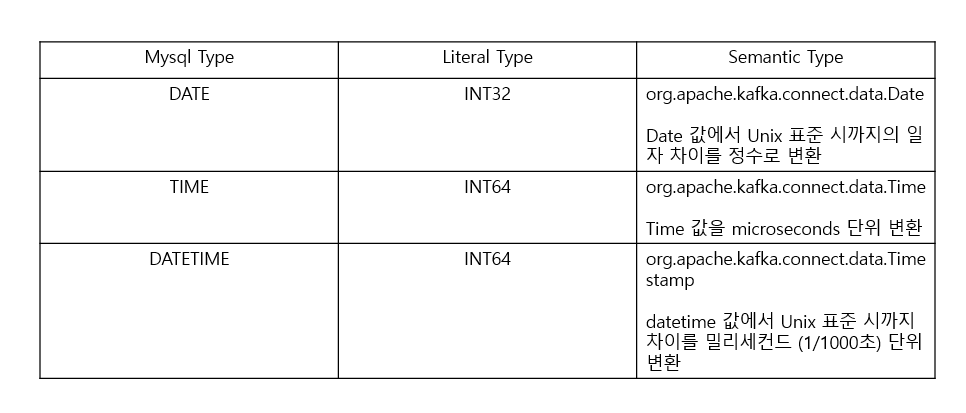
Mysql DATETIME과 TIMESTAMP
- timestamp는 datetime과 달리 timezone 정보를 가짐
- DB는 기본적으로 timezone 설정 필요
- datetime은 클라이언트에서 입력한 값 그대로 DB에 저장되지만 timestamp는 입력 값이 UTC로 변환 되어 DB 저장
- ex) 한국에서 11:00를 입력 시 datetime은 그대로 11:00이 저장되지만 timestamp는 02:00가 저장됨 (저장 시점의 UTC)
- DB 저장 값을 클라이언트에서 출력할 때는 datetime은 DB 저장된 값을 그대로 출력하지만, timestamp는 DB 값을 timezone 설정에 따라 변환한 뒤 출력
Debezium에서 timestamp 타입 변환
- debezium은 datetime의 경우 int64 타입으로 변환하지만 timestamp는 문자열로 변환
- 문자열로 적용 시 UTC timezone을 적용하여 변환됨
- debezium connector 설정 중
database.connectionTimezone = Asia/Seoul은 UTC를 KST로 변환하지 못함- 한국 시간 2022년 11월 22일 13시 30분 37초 timestamp를 debezium에서 ‘2022-11-22T04:30:47Z’와 같은 문자열로 변환함
- 해당 문자열을 JDBC sink connector에서 인식하기 위해서는 timestamp 형 변환이 필요하므로 SMT 적용 필요
문자열 timestamp 처리를 위한 SMT
CREATE TABLE orders_timestamp_tab(
order_id int NOT NULL PRIMARY KEY,
order_datetime datetime NOT NULL,
order_timestamp timestamp NOT NULL,
customer_id int NOT NULL,
order_status varchar(10) NOT NULL,
store_id int NOT NULL) ENGINE=InnoDB;
CREATE TABLE orders_timestamp_tab_sink(
order_id int NOT NULL PRIMARY KEY,
order_datetime datetime NOT NULL,
order_timestamp timestamp NOT NULL,
customer_id int NOT NULL,
order_status varchar(10) NOT NULL,
store_id int NOT NULL) ENGINE=InnoDB;
// debezium source connector
{
"name" : "mysql_cdc_oc_source_timestamp_tab",
"config" : {
"connector.class" : "io.debezium.connector.mysql.MysqlConnector",
"task.max" : "1",
"database.hostname" : "localhost",
"database.port" : "3306",
"database.user" : "connect_dev",
"database.password" : "connect_dev",
"database.allowPublicKeyRetrieval" : "true", // mysql 8.0부터는 true여야 접속 가능 (TLS 설정)
"database.server.id" : "10022", // DB 서버 별로 다르게 지정해야 함
"database.server.name" : "test01",
"database.include.list" : "oc",
"table.include.list" : "oc.orders_timestamp_tab",
"database.history.kafka.bootstrap.servers" : "192.168.56.101:9092",
"database.history.kafka.topic" : "schema_changes.mysql.oc",
"key.converter" : "org.apache.kafka.connect.json.JsonConverter",
"value.converter" : "org.apache.kafka.connect.json.JsonConverter",
"time.precision.mode" : "connect",
"database.connectionTimezone" : "Asia/Seoul",
"transforms" : "unwrap",
"transforms.unwrap.type" : "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones" : "false"
}
}
// jdbc sink connector
{
"name" : "mysql_jdbc_sink_timestamp_tab",
"config" : {
"connector.class" : "io.confluent.connect.jdbc.JdbcSinkConnector",
"tasks.max" : "1",
"topics" : "oc.orders_timestamp_tab",
"connection.url" : "jdbc:mysql://localhost:3306/oc_sink",
"connection.user" : "connect_dev",
"connection.password" : "connect_dev",
"insert.mode" : "upsert",
"pk.mode" : "record_key",
"pk.fields" : "order_id",
"delete.enabled" : "true",
"key.converter" : "org.apache.kafka.connect.json.JsonConverter",
"value.converter" : "org.apache.kafka.connect.json.JsonConverter",
"db.timezone" : "Asia/Seoul",
"transforms" : "conevertTs",
"transforms.convertTs.type" : "org.apache.kafka.connect.transforms.TimestampConvert$Value",
"transforms.convertTs.field" : "order_timestamp",
"transforms.convertTs.format" : "yyyy-MM-dd'T'HH:mm:ss'Z'",
"transforms.convertTs.target.type" : "Timestamp"
}
}
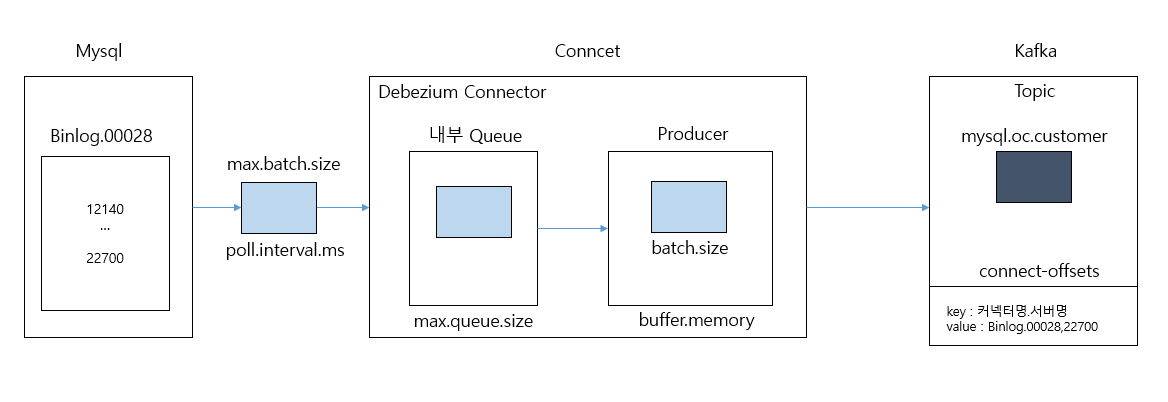
배치 메시지 관련 파라미터
poll.interval.ms: source connector가 배치 메시지를 전송하기 전까지 기다리는 시간 (기본 1000ms)max.batch.size: batch message의 최대 record 건 수 (기본 2048)max.queue.size: producer에 넘기기 전 대기하는 내부 queue의 최대 레코드 크기 (기본 8192), max.batch.size 보다 커야함max.queue.size.in.bytes: producer에 넘기기 전 대기하는 내부 queue의 최대 메모리 크기 (기본 0)- max.queue.size와 max.queue.size.in.bytes가 동시에 설정되어 있으면 어느 한 조건만 만족해도 되는 크기로 queue 크기가 정해짐
Source 테이블의 스키마 변경 유형에 따른 자동 스키마 반영
- 스키마 호환성보다 우선 시 됨
컬럼 추가
- source 테이블의 null 가능한 숫자형, date, datetime, timestamp 컬럼들은 정상적으로 자동 반영, 다만 datetime의 경우는 datetime(3)으로 변형되어 반영
- source 테이블의 not null 컬럼은 반드시 default 값을 명시적으로 선언해주어야 함 (schema registry 적용 시 문제 발생)
- varchar 컬럼 추가 시 sink 테이블은 text로 변환됨
- varchar 컬럼을 not null로 default 값 설정해서 추가하면 sink 테이블은 text를 default 값으로 변경하지 못해서 장애 발생 -> 수동 변경 권장
- default는 저장 공간을 미리 할당해야 하는데, text의 경우 가변 길이 데이터 타입이므로 필드가 차지하는 저장 공간을 미리 알 수 없음
정수형 컬럼 추가
alter table customers add column (age int);
Not Null 컬럼 추가 (default 필수)
alter table customers add column (age int not null default 0);
alter table customers add column (date date not null default '2022-11-25');
alter table customers add column (datetime datetime not null default '2022-11-25 13:00:00');
Varchar Null 컬럼 추가
alter table customers add column (address varcher(100));
Varchar Not Null 컬럼 추가
alter table customers add column (address varcher(100) not null default 'test address');
- insert 시점에 sink connector 오류 발생
- __connect_offsets 확인 시 위 메시지를 읽지도 못함
컬럼 타입 변경
- source 테이블의 컬럼 타입 변경은 sink 테이블에서 반영되지 못함
- 수동 변경 필요
컬럼 타입 삭제
- source 테이블의 컬럼 삭제는 sink 테이블에서 반영되지 못함
- 수동 변경 필요
컬럼명 변경
- source 테이블의 컬럼명 변경은 sink 테이블에서 이상 반영
- 컬럼이 새로 추가 됨
- 수동 변경 권장
MySQL에서 JDBC Sink PostgreSQL 연동
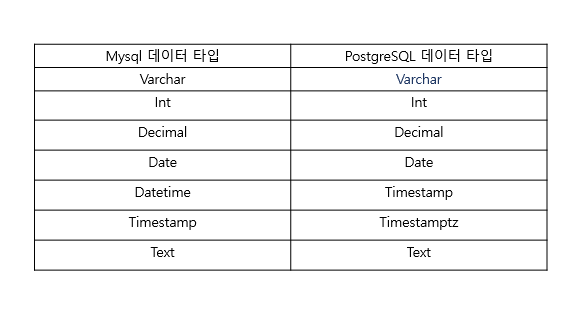
MySQL과 PostgreSQL간 Date와 Time 관련 데이터 타입 변환
- mysql의 date / time / datetime 변환을 위해서는 debezium mysql source connector에서
time.precision.mode=connect를 반드시 설정 - date, time, datetime은 int로 변환되지만 timestamp는 문자열로 변환
- mysql의 date, time, timestamp는 postgresql로 정상 입력됨
- mysql의 timestamp는 JDBC postgresql sink connector에서 SMT를 이용하여 timestamp 형태로 변환되어야 함
- 이 때 sink connector의
db.timezone = Asia/Seoul을 설정하지 않아도 자동으로 postgreSQL의 DB timezone을 반영하여 입력됨
환경 구축
sudo apt update / sudo apt -y upgrade
sudo apt install postgresql postgresql-client
sudo su - postgres
cd /etc/postgresql/12/main
- postgres os 사용자로 로그인
listen_addresses=`*`
wal_level = logical
- postgresql.conf의 설정 변경
- wal_level
- minimal : 가장 적은 양의 정보를 로그에 기록
- replica : 주로 스트리밍 복제에 사용
- logical : 논리적 복제를 위한 모든 정보 로그에 기록
# "logic" is for unix domain socket connections only
local all all md5
# IPv3 local connections:
host all all 0.0.0.0/0 md5
- pg_hba.conf의 아래 IPv4 address를 0.0.0.0/0으로 변경
sudo systemctl restart postgresql
sudo su - postgres
psql
- postgresql 재기동 및 psql 접속
create user connect_dev password 'connect_dev';
alter user connect_dev createdb;
grant all privileges on database postgres to connect_dev;
psql -h localhost -U connect_dev -d postgres
- 새로운 user 생성 및 postgres DB 접속 ``` create schema ops_sink; // mysql에서 db에 해당 set search_path = ops_sink; // default schema 설정
CREATE TABLE customers_sink( customer_id int NOT NULL PRIMARY KEY, email varchar(255) NOT NULL, name varchar(255) NOT NULL);
- 신규 스키마 생성
```json
// postgresql DB 대상 jdbc sink connector
{
"name" : "postgres_jdbc_sink_timestamp_tab",
"config" : {
"connector.class" : "io.confluent.connect.jdbc.JdbcSinkConnector",
"tasks.max" : "1",
"topics" : "mysqlavro_ops_customers",
"connection.url" : "jdbc:postgresql://localhost:5432/postgres",
"connection.user" : "connect_dev",
"connection.password" : "connect_dev",
"insert.mode" : "upsert",
"pk.mode" : "record_key",
"pk.fields" : "customer_id",
"delete.enabled" : "true",
"key.converter" : "io.confluent.connect.avro.AvroConverter",
"value.converter" : "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url" : "http://localhost:8081",
"value.converter.schema.registry.url" : "http://localhost:8081",
"transforms" : "conevertTs",
"transforms.convertTs.type" : "org.apache.kafka.connect.transforms.TimestampConvert$Value",
"transforms.convertTs.field" : "order_timestamp",
"transforms.convertTs.format" : "yyyy-MM-dd'T'HH:mm:ss'Z'",
"transforms.convertTs.target.type" : "Timestamp"
}
}
"db.timezone" : "Asia/Seoul"설정 필요 없음 (postgreSQL DB 설정 따름)
스키마 변경 유형에 따른 스키마 반영
- Mysql to Mysql
- source 테이블의 null 가능한 숫자형, date, datetime 컬럼들은 정상 반영
- datetime인 경우 datetime(3)으로 반영
- varchar인 경우 text로 반영
- timestamp의 경우 문자열로 변경됨
- source 테이블의 not null은 sink 테이블에서 제대로 인지하지 못해서 null로 적용됨
- varcahr 컬럼 not null로 default 값 추가 시 sink에서 반영하지 못하고 장애 발생
- Mysql to PostgreSQL
- source 테이블의 null 가능한 숫자형, date, datetime 컬럼들은 정상 반영
- datetime인 경우 timestamp로 반영
- varchar인 경우 text로 반영
- timestamp의 경우 문자열로 변경됨
- source 테이블의 not null은 sink 테이블에서 제대로 인지하지 못해서 null로 적용됨
- varcahr 컬럼 not null로 default 값 추가 시 postgresql sink에서 정상적으로 default 값을 반영
- 컬럼 타입 변경 / 삭제 / 컬럼명 변경은 두 경우 동일함
Debezium PostgreSQL CDC Source Connector
DML -> WAL (트랜잭션 로그파일) -> Datafile (Redolog)
Replication 메커니즘 비교
mysql: binary log를 dump로 slave에 전송해서 slave는 log dump 바탕으로 sql을 생성하여 DB 반영 (logical 복제)postgresql: WAL file을 chunk 단위로 실시간으로 보내고 받는 쪽에서는 받은 WAL file 그대로 복제함 (dump가 아니며 SQL 변환도 하지 않은 physical 복제)
PostgreSQL Logical Replication
- postgresql도 mysql 처럼 publisher-subscriber 모델의 logical 복제 도입
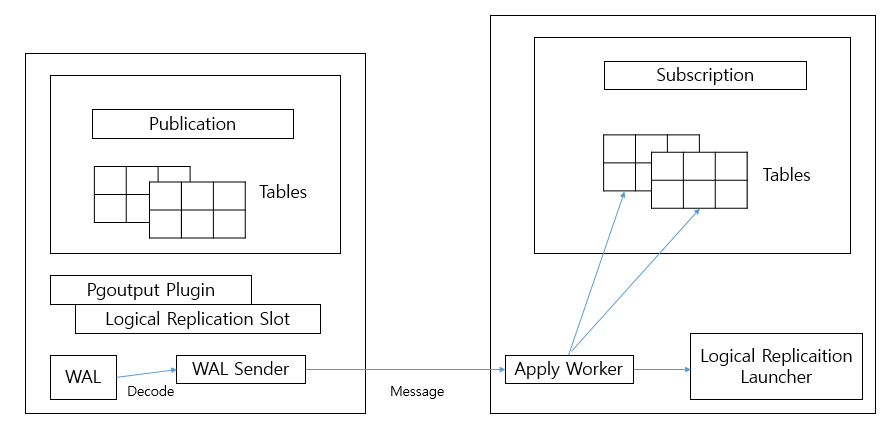
- 복제 대상 테이블을 선정해서
Publication에 등록 - WAL을 decoding 해서
WAL sender로 전송 (pgoutput plugin이 WAL을 디코딩하는 용도) Apply Worker가 SQL로 변환하여 테이블에 반영Logical replication Slot에서 WAL이 어디까지 보내졌는지 등의 관리 수행
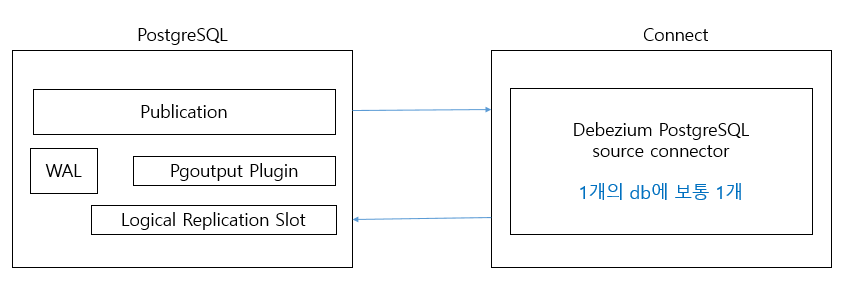
- 기존 WAL Sender를 통해 subscriber에 전송 대신 source connector가 붙어서 처리
- pgoutput에서 적정 데이터를 뽑아서 전송
{
"name" : "postgres_cdc_oc_source",
"config" : {
"connection.class" : "io.debezium.connector.postgresql.PostgresConnector",
"tasks.max" : "1",
"database.hostname" : "192.168.56.101",
"database.port" : "5432",
"database.user" : "connect_dev",
"database.password" : "connect_dev",
"database.dbname" : "oc",
"database.server.name" : "pg01",
"plugin.name" : "pgoutput", // decoding plugin 유형으로 반드시 pgoutput으로 설정
"slot.name" : "debezium_01", // 없으면 새로 생성
"publication.name" : "dbz_publication", // 기본 명은 dbz_publication 이며, 없으면 자동 생성 모드에 따라 생성하거나 오류 발생
"publication.autocreate.mode" : "all_tables", // all_tables : DB 내 모든 테이블 등록, filtered: include list 따라 테이블 등록, disabled: 오류 발생
"schema.include.list" : "public",
"table.include.list" : "public.customers, public.orders",
"key.converter" : "org.apache.kafka.connect.json.JsonConverter",
"value.converter" : "org.apache.kafka.connect.json.JsonConverter",
"transforms" : "unwrap",
"transforms.unwrap.type" : "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones" : "false"
}
}
** 부록 **
- publication, replication slot 삭제
drop publication dbz_publication; SELECT pg_drop_replication_slot('debezium_01'); - publication, replication slot 확인
select * from pg_replication; select * from pg_replication_slots;