Zookeeper 연동
Zookeeper 개요
- 분산 시스템 간 정보를 신속하게 공유하기 위한 코디네이션 시스템
Zookeeper의 Z node
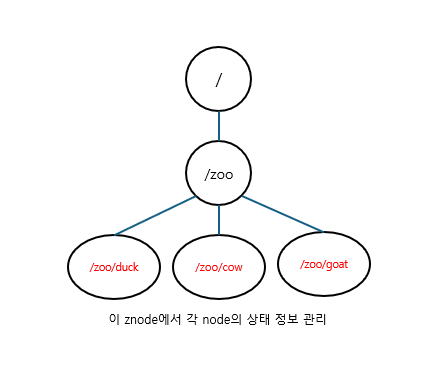
- 분산 시스템에서 리더 노드를 선출
- 개별 노드 간 상태 정보의 동기화를 위한 복잡한 lock 관리 기능
- 개별 노드들은 zookeeper의 znode를 계속 모니터링 하여 znode에 변경 발생 시 watch event가 트리거되어 변경 정보가 개별 노드들에게 통보
- zookeeper 자체에 클러스터링 기능 제공
zookeeper_shell localhost:2181
- shell에 접속 후 파일 구조를 API처럼 호출해서 내용 확인 가능
ls /get /controller
Kafka 클러스터에서 Zookeeper의 역할
- controller broker 선출 (leader election)
- kafka 클러스터 내 broker들의 membership 관리
- broker들의 list, broker join/leave 관리 및 통보
- topic의 partition, replicas 정보 가짐
zookeeper에서 kafka cluster 정보 관리
- 모든 카프카 브로커는 주기적으로 zookeeper에 접속하면서 session heartbeat를 전송하여 자신의 상태를 보고함
- zookeeper는
zookeeper.per.session.timeout.ms이내에 heartbeat를 받지 못하면 해당 브로커의 노드 정보를 삭제하고 controller 노드에게 변경 사실을 통보 - controller 노드는 다운된 broker에서 관리하는 leader 파티션들에 대해 새로운 leader election 수행
- 만일 controller가 다운된 경우 모든 노드에 해당 사실을 통보하고 가장 먼저 접속한 다른 브로커가 controller가 됨
Controller의 Leader Election 수행 프로세스
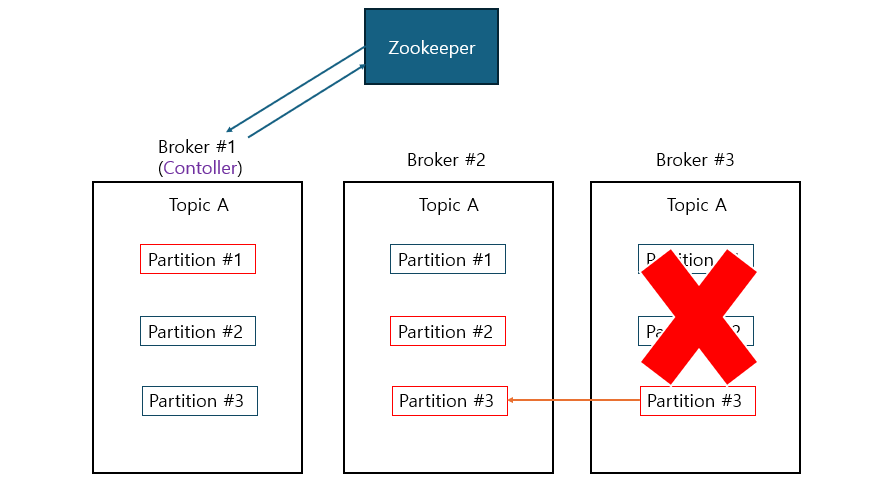
1) broker #3이 shutdown되고 zookeeper는 session timeout 동안 heartbeat이 오지 않으므로 해당 broker 노드 정보 갱신
2) controller는 zookeeper를 모니터링 하던 중 watch event로 broker #3에 대한 down 정보를 받음
3) controller는 다운된 broker가 관리하던 파티션들에 대해 새로운 leader/follower 결정
4) 결정된 새로운 leader/follower 정보를 zookeeper에 저장하고 해당 파티션을 복제하는 모든 broker에게 새로운 leader 정보를 전달하여 새로운 leader로부터 복제 수행 요청
5) controller는 모든 broker에 metadata cache 정보 갱신 요청