Multi-node Kafka Cluster
멀티 노드 카프카 클러스터
- 분산 시스템으로 카프카의 성능과 가용성을 함께 향상 시킬 수 있도록 구성
- 스케일 아웃 기반으로 노드 증설을 통해 메시지 전송과 읽기 성능을 선형적으로 증가시킬 수 있음
- 데이터 복제를 통해 분산 시스템 기반에서 카프카의 최적 가용성 보장
분산 시스템 구성을 위한 중요 요소
- 분산 시스템 도입을 위해서는 성능, 안정성, 가용성 측면에서 상세한 기능 검토가 요구됨
- 분산 시스템은 대량 데이터를 여러 노드간 분산 처리를 통해 처리할 수 있는 큰 성능적 이점을 가지지만 안정성과 가용성 측면에서 상대적인 단점을 가짐 (여러 노드의 데이터 정합 문제)
단일 노드 구성 (scale up)
- H/W를 cpu core, memory, disk 용량 등을 scale up 방식으로 증설하는 것은 한계 (비용, H/W 아키텍처 등)
- 단일 노드에 대해서만 가용성 구성을 강화하면 되므로 매우 안정적인 시스템 구성 가능
- 다양한 성능 향상 기법 도입 쉬움
다수 분산 노드 구성 (scale out)
- 개별 H/W를 scale out 방식으로 증설하여 선형적으로 데이터 성능 처리 수행
- 다수의 H/W가 1/N의 데이터를 처리하므로 하나의 노드에서만 장애가 발생해도 올바른 데이터 처리가 되지 않음
- 다수 H/W를 관리해야 하므로 빈번한 장애 관리
멀티 브로커 설치
- 3개의 broker를 VM에 구성
- 개별 broker를 각각 서로
server.properties설정- 서로 다른 log.dirs 지정
- 서로 다른 port 적용 (같은 노드인 경우)
- 서로 다른 broker.id 설정
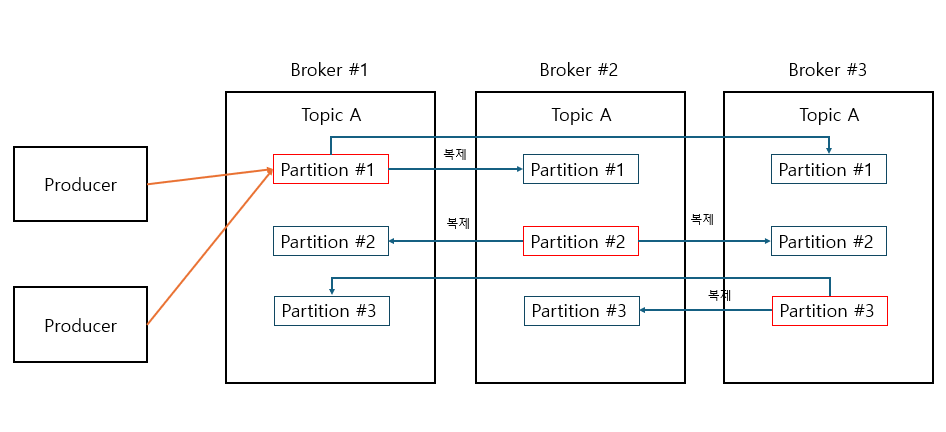
Kafka Replication
- 카프카 가용성의 핵심
- replication은 topic 생성 시 replication factor 설정 값을 통해 구성
- 지정 값은 원본과 복제 파티션 모두 포함
- replication factor의 개수는 broker의 파티션 개수보다 클 수 없음
kafka-topics --bootstrap-server localhost:9092 --create --topic 토픽명 --partitions 3 --replication-factor 2 - partition 3개로 지정 시 broker가 3개면 partition 1개씩 할당됨
- replication-factor 2로 지정 시 각 파티션 별로 2개씩 복제 (follower) 생성
Leader와 Follower
- producer와 consumer는 leader 파티션을 통해서만 작업 수행
- kafka 2.4 이후 consumer는 follower에서 읽어들일 수 있음
- replication은 leader에서 follower로만 이루어짐
- controller (leader broker)가 broker의 replication 관리
Client에서 Multi Broker 접속
- bootstrap.servers는 broker listener의 list
- 모든 broker를 작성하는 것이 필수는 아니지만 하나만 작성 시 해당 브로커가 오류면 클러스터 접속 불가
- 개별 broker 들은 토픽 파티션의 leader와 follwer들의 메타 정보를 서로 공유하고, producer는 초기 접속 시 이 메타정보를 가져와서 접속하려는 파티션이 있는 브로커로 다시 접속
broker들이 공유하는 metadata
Topic A partition 1:
Leader Br#1 Follwer Br#2, Br#3
Topic A partition 2:
Leader Br#2 Follwer Br#1, Br#3
Topic A partition 3:
Leader Br#3 Follwer Br#1, Br#2