Kafka Consumer
Consumer 개요
- 브로커의 topic 메시지 읽는 역할 수행
- 모든 consumer 들은 고유한 group id를 가지는 consumer group에 속해야 함
- Fetcher, ConsumerClientNetwork 등의 주요 내부 객체와 별도의 HeartBeat Thread를 생성
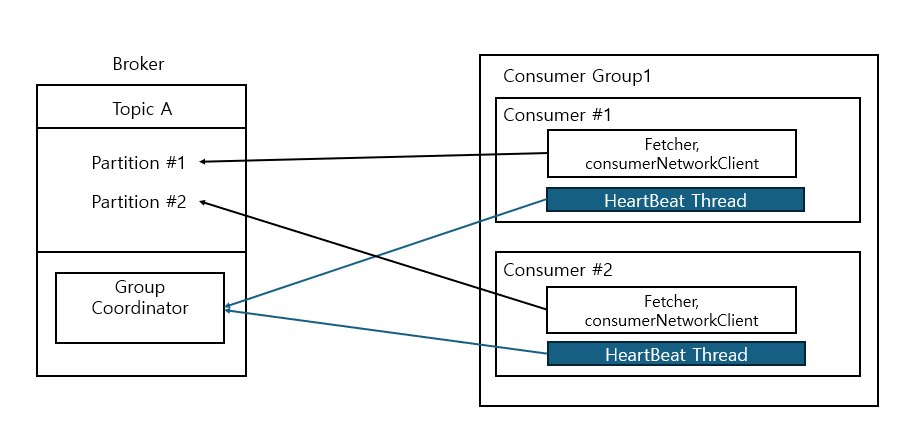
- partition은 consumer group에서 단 하나의 consumer에만 할당됨
- 동일 consumer group 내 consumer들은 작업량을 최대한 균등하게 분배
- 서로 다른 consumer group의 consumer들은 분리되어 독립적으로 동작
kafka-console-consumer --bootstrap-server localhost:9092 --group 그룹명 --topic 토픽명
--property pring.key=true --property print.partition=true
Simple Consumer
String topic = "simple-topic";
Properties props = new Properties();
props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.56.101:9092");
props.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "group-01");
KafkaConsumer<String,String> kafkaConsumer = new KafkaConsumer<>(props);
kafkaConsumer.subscribe(List.of(topic));
while(true)
{
ConsumerRecords<String,String> consumerRecords = kafkaConsumer.poll(Duration.ofMillis(1000));
for(ConsumerRecord record : consumerRecords)
{
logger.info("key : {} value : {} partitions : {}". record.key(), record.value(), record.partition());
}
}
kafkaConsumer.close();
- subscribe에 topic은 collection 또는 pattern으로 지정 가능
kafkaConsumer.poll(Duration.ofMillis(1000))- 가져올 데이터가 하나도 없는 경우 1000ms 만큼 기다린 후 return
Custom 데이터 읽기
Deserializer 구현
public class OrderDeserialzer implements Deserializer<Order> {
ObjectMapper objectMapper = new ObjectMapper().registerModule(new JavaTimeModule());
@override
public Order deserializer(String topic, byte[] data) {
Order order = null;
try {
order = objectMapper.readValue(data, Order.class);
} catch (IOException e) {
...
}
return order;
}
}
OrderSerdeConsumer
props.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, OrderDeserializer.class.getName());
KafkaConsumer<String, Order> kafkaConsumer = new KafkaConsumer<String, Order>(props);
ConsumerRecords<String,Order> records = kafkaConsumer.poll(Duration.ofMilis(1000));
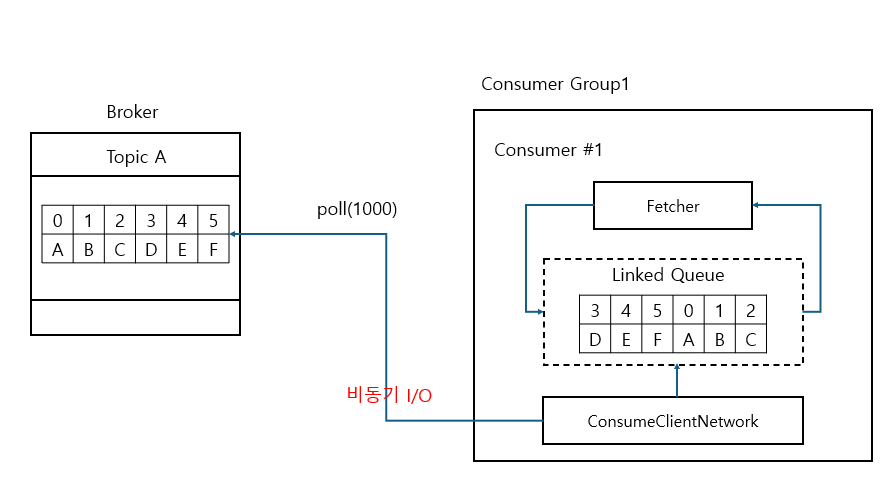
- Fetcher는 Linked Queue에 데이터가 없는 경우 ConsumerClient Network에 데이터를 가져올 것을 요청
- Linked Queue에 데이터가 있는 경우 Fetcher는 데이터 가져오고 poll() 수행 완료
Consumer Fetcher 관련 주요 설정 파라미터
- fetch.min.bytes
- fetcher가 record를 읽어들이는 최소 bytes (default = 1)
- fetcher가 ConsumerClient Network를 통해 record를 읽어오도록 했을 때 지정한 bytes만큼 쌓이지 않으면 broker는 전송하지 않음
- fetch.max.wait.ms
- 브로커에 fetch.min.bytes 이상의 메시지가 쌓일 때까지 최대 대기 시간 (default = 500ms)
- 이 시간까지 쌓이지 않으면 그냥 가져감
- fetch.max.bytes
- fetcher가 브로커에서 한 번에 가져올 수 있는 최대 데이터 bytes (default 50MB)
- max.partition.fetch.bytes
- fetcher가 브로커에서 파티션 별 한 번에 가져올 수 있는 bytes
- max.poll.records
- fetcher가 브로커에서 한 번에 가져올 수 있는 레코드 수 (default 500)
- fetch.max.bytes 초과하지 않는 범위내에서 레코드 수 제한함
만약 가져올 데이터가 많은 경우 max.partition.fetch.byte 크기를 조절해야 하고, 적다면 fetch.min.bytes 크기를 조절해야 함
- 가장 최신의 offset 데이터를 가져오고 있다면 fetch.min.bytes 만큼 가져오고 있거나 데이터가 min만큼 차지 않아서 fetch.min.bytes만큼 기다렸다가 return 한 경우일 수 있음
- 오랜 과거 offset 데이터를 가져온 다면 최대 max.partition.fetch.bytes만큼 파티션에서 읽은 뒤 반환
Consumer의 auto.offset.reset
__consumer_offsets에 consumer group이 offset 정보를 가지고 있지 않을 시 consumer가 접속 시 파티션의 처음 offset부터 가져올 것인지, 마지막 offset 이후부터 가져올 것인지를 설정- 만약 가지고 있으면 기록된 offset을 읽음
- offsets.retention.minutes
- __consumer_offsets에 유지되는 offset 기간 (default 7일)
- consumer가 종료되어도 offset은 유지됨
- 해당 topic이 삭제되고 재생성되는 경우는 topic에 대한 consumer group의 offset 정보는 0으로 기록됨
Group Coordinator와 Consumer Group
- consumer group 내 새로운 consumer가 추가되거나 기존 consumer가 종료될 때, 또는 topic에 새로운 partition이 추가될 때 broker의 group coordinator는 consumer group내의 consumer 들에게 파티션을 재할당하는 rebalancing 수행 지시
- consumer group은 group coordinator를 통해 __consumer_offsets 토픽에 그룹 내 consumer들의 offset을 기록하는데, __consumer_offsets에는 50개의 파티션이 존재, consumer group 별 작성할 파티션의 리더인 브로커가 group coordinator가 됨
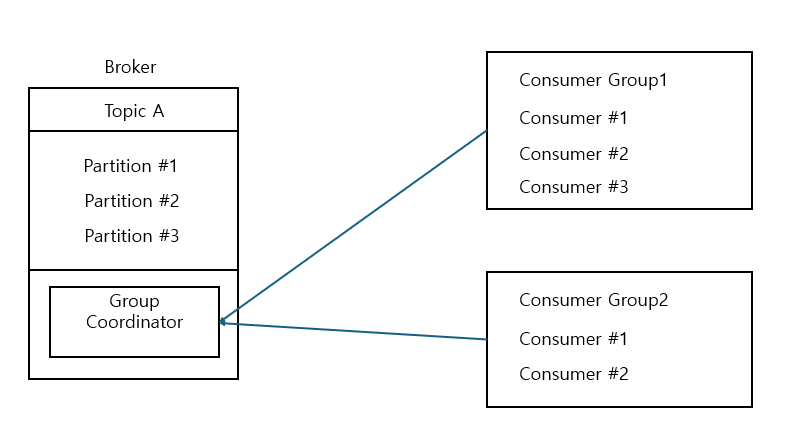
Group Coordinator
- consumer들의 join group 정보
- partition 매핑 정보
- consumer의 heartbeat 관리
1) consumer group 내 consumer가 broker에 최초 접속 요청 시 group coordinator가 생성
2) 동일 group.id로 여러 개의 consumer가 broker의 group coordinator로 접속
3) 가장 빨리 group에 join 요청 한 consumer에게 leader consumer로 지정
4) leader는 파티션 할당 전략에 따라 consumer들에게 파티션 할당
5) leader는 최종 할당 된 파티션 정보를 group coordinator에게 전달
6) 정보 전달 성공을 공유한 뒤 개별 consumer들은 할당된 파티션에서 메시지 읽음
Consumer Group Status
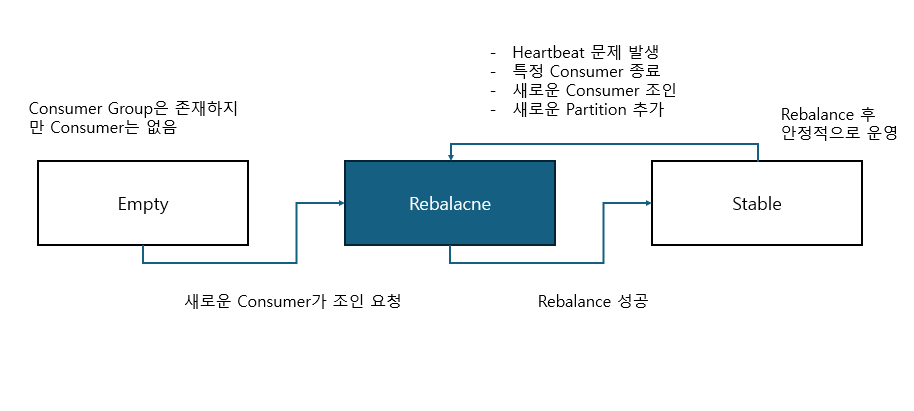
Consumer 스태틱 그룹 멤버쉽
- 많은 consumer를 가지는 consumer group에서 rebalance가 발생하면 모든 consumer들이 rebalance를 수행하므로 많은 시간이 소모되고 대량 데이터 처리 시 Lag가 길어질 수 있음
-
유지 보수 차원의 consuemr restart도 rebalance를 초래하므로 불필요한 rebalance를 발생시키지 않는 법 필요
- consumer group 내의 consumer 들에게 고정된 id 부여
- consumer 별로 consumer group 최초 조인 시 할당된 파티션을 그대로 유지하고 consumer가 shutdown되어도
session.timeout.ms내에 재기동되면 rebalance 수행되지 않고 기존 파티션이 재할당 됨 - 스태틱 그룹 멤버십을 적용할 경우 session.timeout.ms를 좀 더 큰 값으로 설정
props.setProrperty(ConsumerConfig.GROUP_INSTANCE_ID_CONFIG, "group-02");
Heartbeat와 poll() 관련 주요 파라미터
- heartbeat.interval.ms (default = 3000)
- heartbeat thread가 heartbeat를 보내는 간격
- session.timeout.ms 보다 작게 설정되어야 함
- session.timeout.ms의 1/3 보다 낮게 설정 권장
- session.timeout.ms
- broker(group coordinator)가 consumer에서 오는 heartbeat를 기다리는 최대 시간
- 이 시간 내에 heartbeat를 받지 못할 시 rebalancing 명령
- max.poll.interval.ms
- heartbeat는 정상적으로 보내도 실제 polling을 제대로 수행하지 못하는 기능 장애 방지
- 이전 poll()을 호출 후 다음 poll()까지 broker가 기다리는 시간
- 해당 시간 내에 poll() 요청이 오지 않으면 rebalancing 명령
Wakeup를 이용하여 Consumer 효과적으로 종료
Thread mainThread = Thread.currentThread()
Runtime.getRuntime().addShutdown(new Thread(){
public void run()
{
kafkaConsumer.wakeup();
try{
mainThread.join();
}catch(InterruptedException e)
{
...
}
}
});
try{
while(true){
consumerRecord<String,String> consumerRecords = kafkaConsumer.poll(Duration.ofMilis(1000))
for(consumerRecords record : consumerRecords)
{
log(...)
}
}
}catch(WakeupException e)
{
// ignore
}finally
{
kafkaConsumer.close();
}
- while 무한 루프를 중지하기 위해 interrupt signal을 통헤 강제 종료를 시켜야하는데, 그렇게 되면 group coordinator에서 session.timeout까지 consumer의 상태를 알 수 없음
- shutdown 이벤트 등록해서 mainThread 종료 시 wakeup 호출하도록 명령하고, WakeupException을 발생시켜 무한 루프 탈출
Consumer Rebalancing Protocol
Eager 모드
- rebalancing 수행 시 기존 consumer의 모든 파티션 할당 취소하고 잠시 메시지를 읽지 않음
- 이후 새롭게 consumer에 파티션을 할당받고 다시 메시지를 읽음
- lag가 상대적으로 크게 발생
- 파티션 할당 전략(
partition.assignment.strategy) 중 Range, Round Robin, Sticky 방식이 여기에 해당
Cooperative 모드
- rebalance 수행 시 기존 consumer들의 모든 파티션 할당을 취소하지 않고 대상이 되는 consumer들에 대해서 파티션에 따라 점진적으로(Incremental) consumer를 할당해가며 수행
- 전체 consumer가 메시지 읽기를 중지 하지 않으며 개별 consumer가 협력적으로 영향을 받는 파티션만 Rebalancing
- 많은 consumer를 가지는 consumer group에서 활용도 높음
- 파티션 할당 전략 중 Cooperative Sticky에 해당
Consumer 파티션 할당 전략 유형
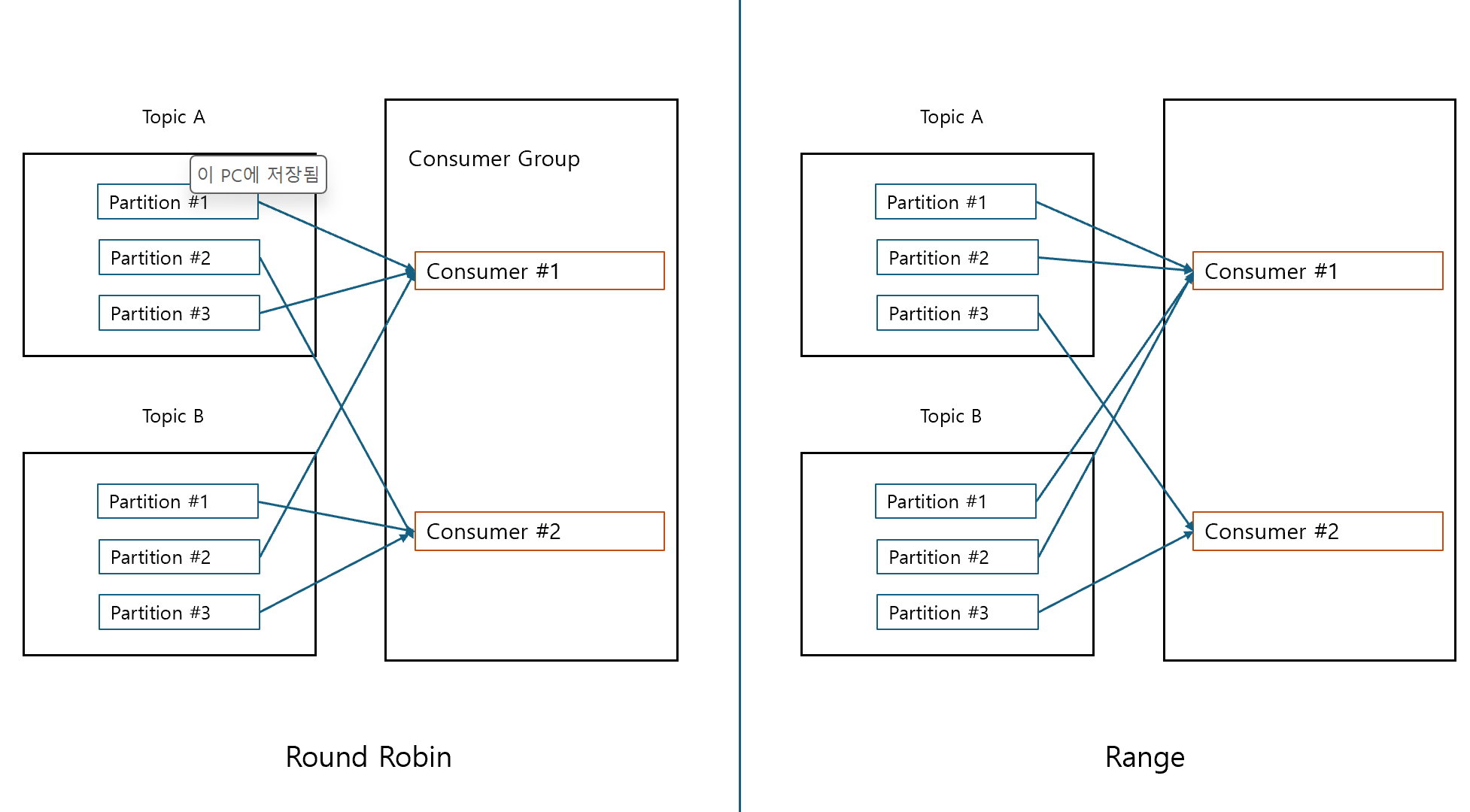
- Range 할당 전략
- 서로 다른 2개 이상의 토픽을 consumer들이 subscribe할 시 토픽 별 동일한 파티션을 특정 consumer에 할당하는 전략
- 여러 토픽들에서동일한 키 값으로 되어 있는 파티션을 특정 consumer에 할당하여 해당 consumer가 여러 토픽의 동일 키 값으로 데이터 처리를 용이하게 할 수 있도록 지원
- Round Robin 할당 전략
- 파티션별로 consumer들이 균등하게 부하를 분배할 수 있도록 순차적 할당
- Sticky 할당 전략
- 최근 할당된 파티션과 consumer 매핑을 rebalance 수행되어도 가급적 그대로 유지
Round Robin과 Range 비교
Round Robin의 Rebalancing 후 파티션 매핑
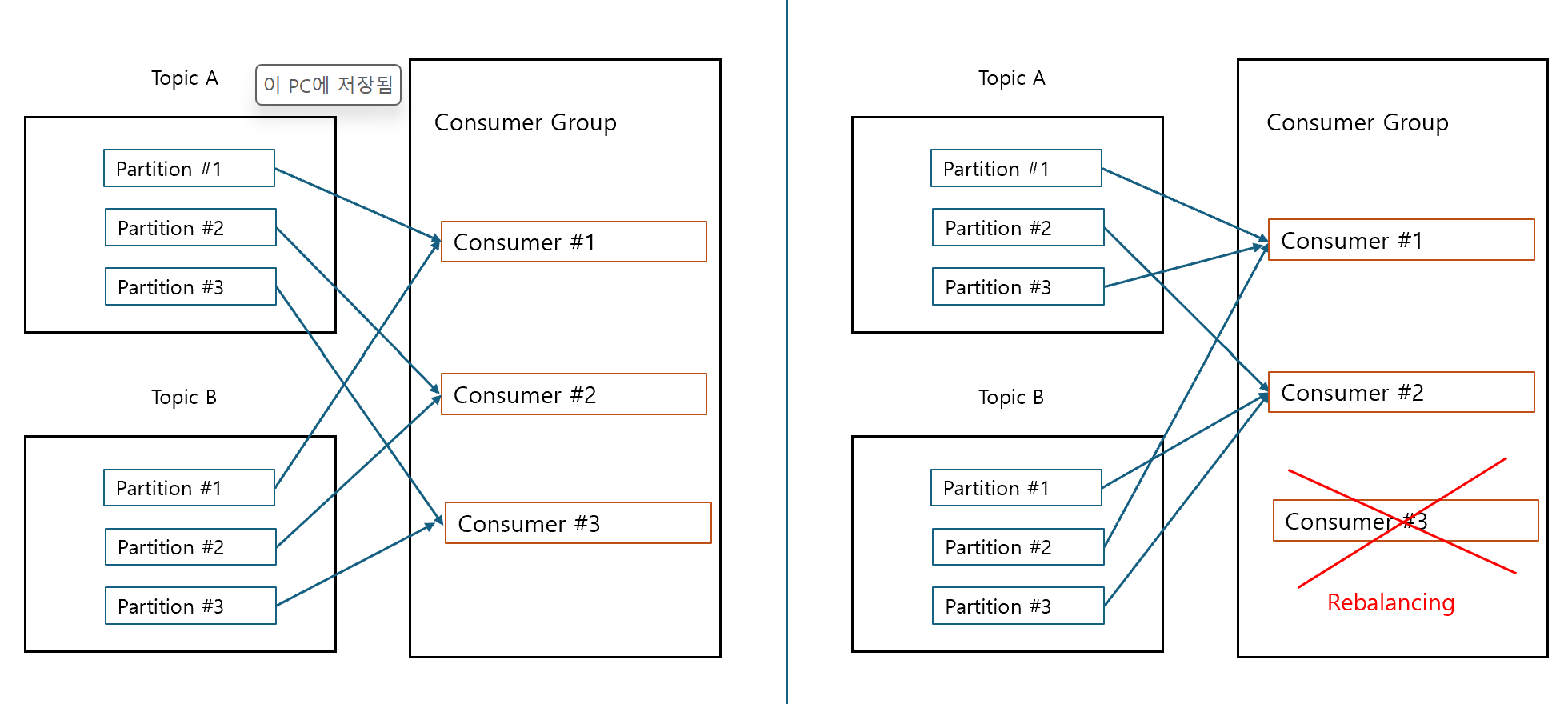
- rebalancing 후 이전의 파티션과 컨슈머의 매핑이 변경 되기 쉬움
Sticky의 Rebalancing 후 파티션 매핑
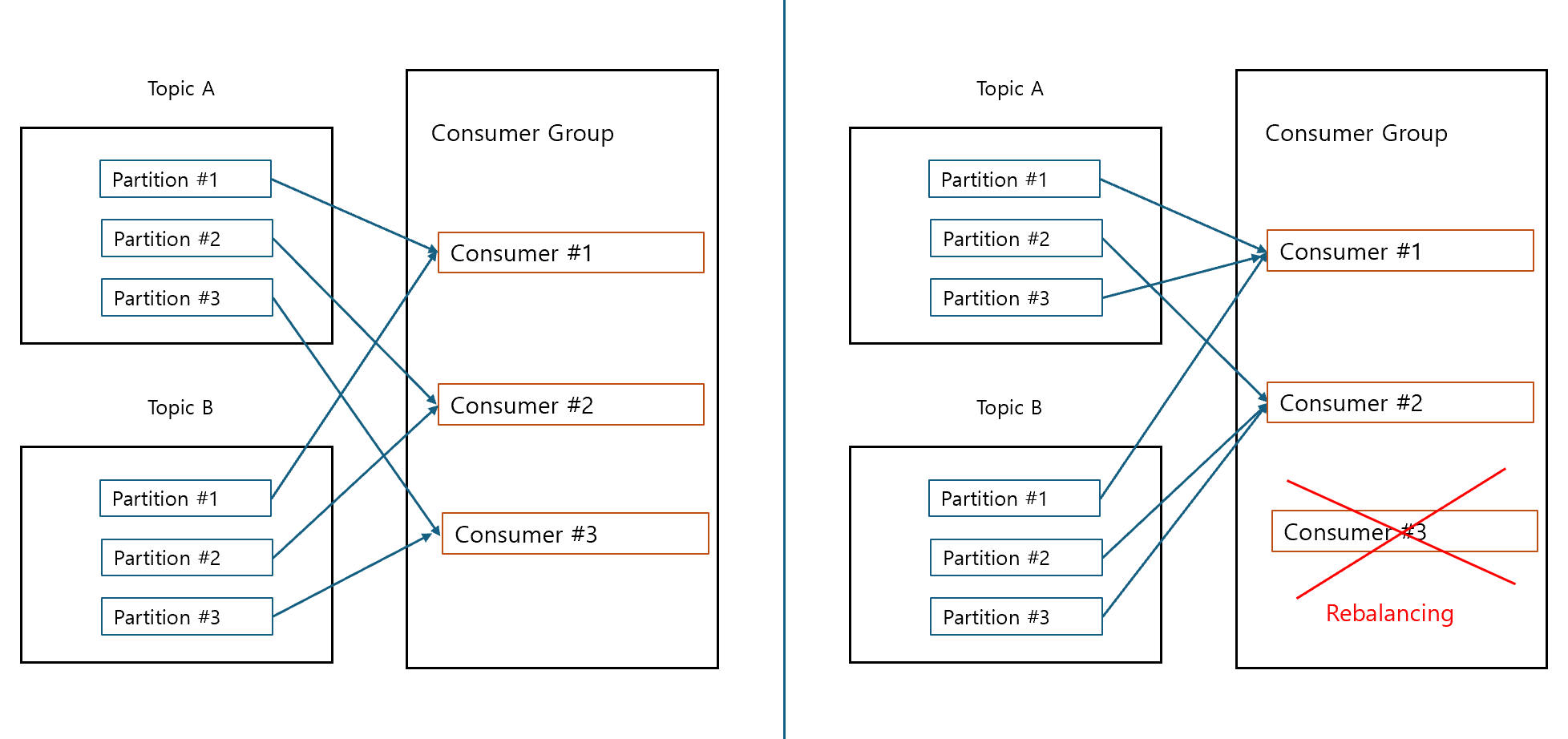
- 각 토픽의 partition 1,2는 유지 후 3만 나눠서 매핑
- sticky도 eager이므로 모두 해제 후 다시 할당함
Cooperative Sticky의 Rebalancing
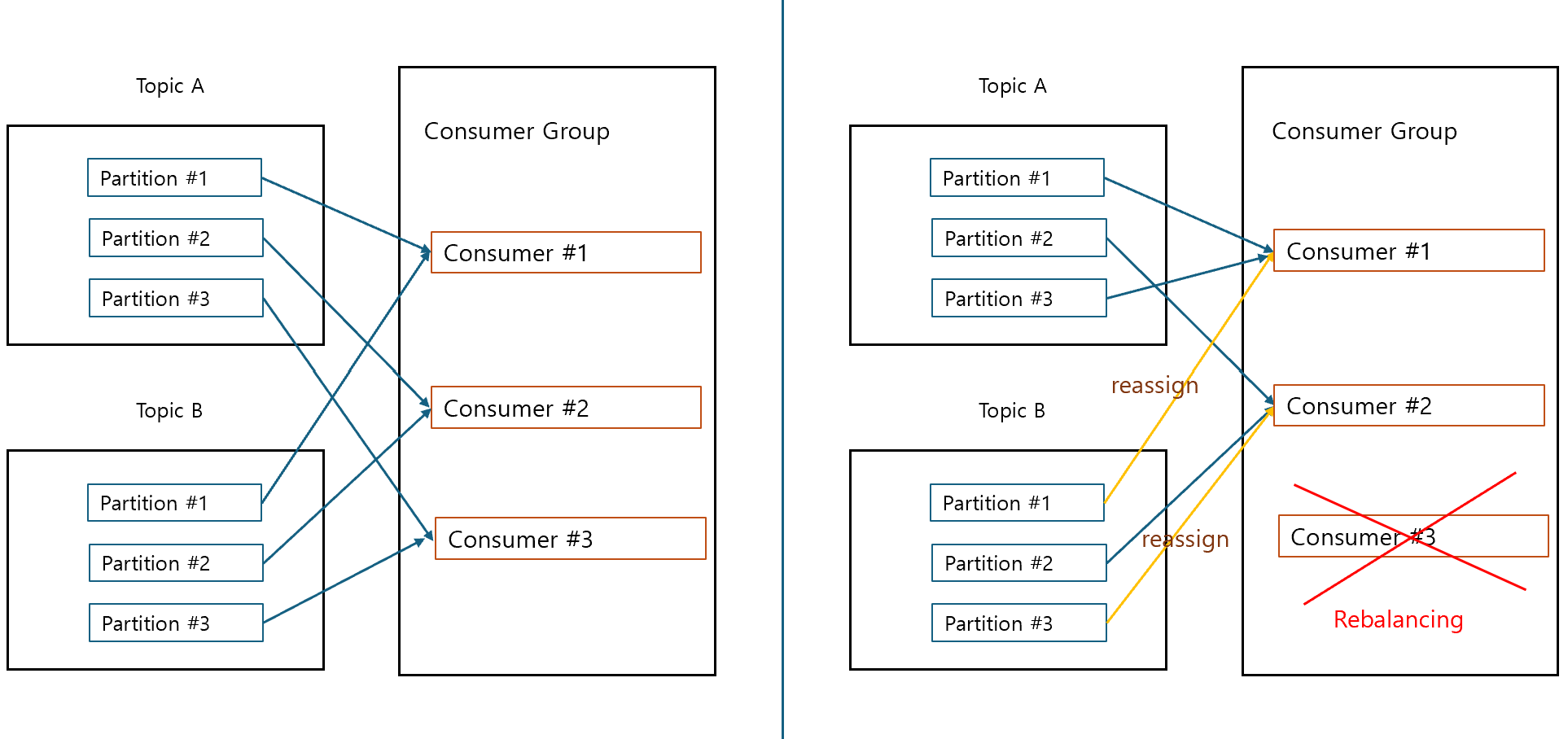
- 모든 매핑을 취소하지 않고 기존 매핑을 유지
- partition 3만 순차적으로 재할당
Offset Commit의 이해

__consumer_offsets에는 consumer group이 특정 topic의 partition 별로 읽기 commit 한 offset의 정보를 가짐- 어느 consumer가 commit 했는 지에 대한 정보는 가지지 않음
- offset 정보는 다음에 읽을 offset임
중복 읽기 상황
- poll()을 통해 읽어들였으나 commit을 하지 못하고 consumer가 죽는 경우 rebalancing을 통해 해당 파티션을 할당 받은 다른 consumer에서는 중복 읽기 발생
읽기 누락 상황
- poll() 수행 후 바로 commit, 가져온 데이터를 처리하는 중 consumer가 죽는 경우 이후 consumer에서는 commit 이후 데이터만 가져오므로 누락됨
Consumer Offset 적용 유형
- Auto Commit : 사용자가 코드로 commit을 기술하지 않아도 consumer가 자동으로 지정된 기간마다 commit 수행
- Manual Commit : 사용자가 명시적으로 commit을 기술, sync와 async가 있음
Consumer의 Auto Commit
- ‘auto.enable.commit= true’ 인 경우 메시지를 브로커에 바로 commit 하지 않고 ‘auto.commit.interval.ms’에 정해진 주기(default 5초)마다 consumer가 자동으로 commit을 수행
- 바로 commit 하지 않으므로 consumer가 죽으면 broker의 commit이 실제 consumer가 읽어온 메시지보다 오래되었으므로, 장애/재가동 및 rebalancing 후 브로커에서 이미 읽어온 메시지를 다시 읽어오는 중복 처리 가능성 있음
- auto.commit.interval.ms에 지정한 시간이 흐른 뒤 수행되는 poll()에서 이전 poll()에서 가져온 메시지에 대한 offset을 commit
- 즉 interval마다 commit하는 것은 이전 poll에 대한 offset
Consumer의 Manual 동기/비동기 Commit
- Sync 방식
- consumer 객체의
commitSync()사용 - 메시지 배치를 poll()을 통해서 읽어오고 마지막 offset을 브로커에 commit 적용
- commit 시점을 사용자가 지정
- broker에 commit 적용이 성공적으로 될 때 까지 blocking 적용
- broker에 commit 적용 실패할 경우 다시 commit 적용 요청
- 비동기 대비 느림
- consumer 객체의
- Async 방식
- consumer 객체의 commitAsync() 메소드를 사용
- broker에 commit 적용이 성공하길 기다리지 않고 계속 메시지 읽어옴
- broker에 commit 적용이 실패해도 다시 commit 시도 안함
- 따라서 consumer 장애 혹은 rebalance 시 한 번 읽은 메시지를 다시 중복해서 가져올 수 있음
- 동기 대비 빠름
// auto commit 비활성화
// props.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "6000");
props.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT, "false");
props.setProperty(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFI, CooperativeStickyAssignor.class.getName());
...
// commitAsync
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofMillis(1000));
kafkaConsumer.commitAsync(new OffsetConsumerCallback(){
@override
public void onComplete(...){}
});
// commitSync
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofMillis(1000));
if(consummerRecords.count() > 0)
kafkaConsumer.commitSync();
- auto commit은 property에서
ENABLE_AUTO_COMMIT_CONFIG를 true로 설정하고 commitSync(), commitAsync()를 호출하지 않을 시 수행 됨
Consumer에서 Topic의 특정 파티션만 할당하기
- consumer에게 여러 개의 파티션이 있는 topic에서 특정 파티션만 할당 가능
- 배치 처리 시 특정 key 레벨의 파티션을 특정 consumer에 할당하여 처리할 경우 적용
- kafkaConsumer의 assign() 메소드에 TopicPartition 객체로 특정 파티션을 인자로 입력하여 할당
TopicPartition tp = new TopicPartition(topicName, 0);
kafkaConsumer.assign(Arrays.asList(tp));
- 0번 파티션을 할당
- 할당 되는 파티션은 무조건 leader
Topic 특정 파티션의 특정 offset부터 읽기
- 특정 메시지가 누락되었을 경우 해당 메시지를 다시 읽어오기 위해 유지보수 차원에서 사용
TopicPartition tp = new TopicPartition(topicName, 0);
kafkaConsumer.assign(Arrays.asList(tp));
kafkaConsumer.seek(tp, 6L)
- 만약 기존 group id를 사용하는 consumer를 통해 작업을 수행하고 commit 수행 시 __commit_offsets를 갱신 할 수 있으므로 유의
- manual commit으로 설정하고 commit을 수행하면 안됨 (디버깅 용)