KSQLDB 개요
KSQLDB
SQL 만으로 쉽게 streaming 데이터의 가공/ 변환/ 분석 수행
적용 사례
- 고객 360
- 데이터 웨어하우스
- 사기 탐지
- IoT
- 스트리밍 데이터 파이프라인
- 고객 충성도 시스템 구축
- 개인 맞춤형 프로모션 생성
- 실시간 주문 배송 추적
- 지리적 위치 기반 알림 및 프로모션 생성
Streams API 기반 데이터 처리
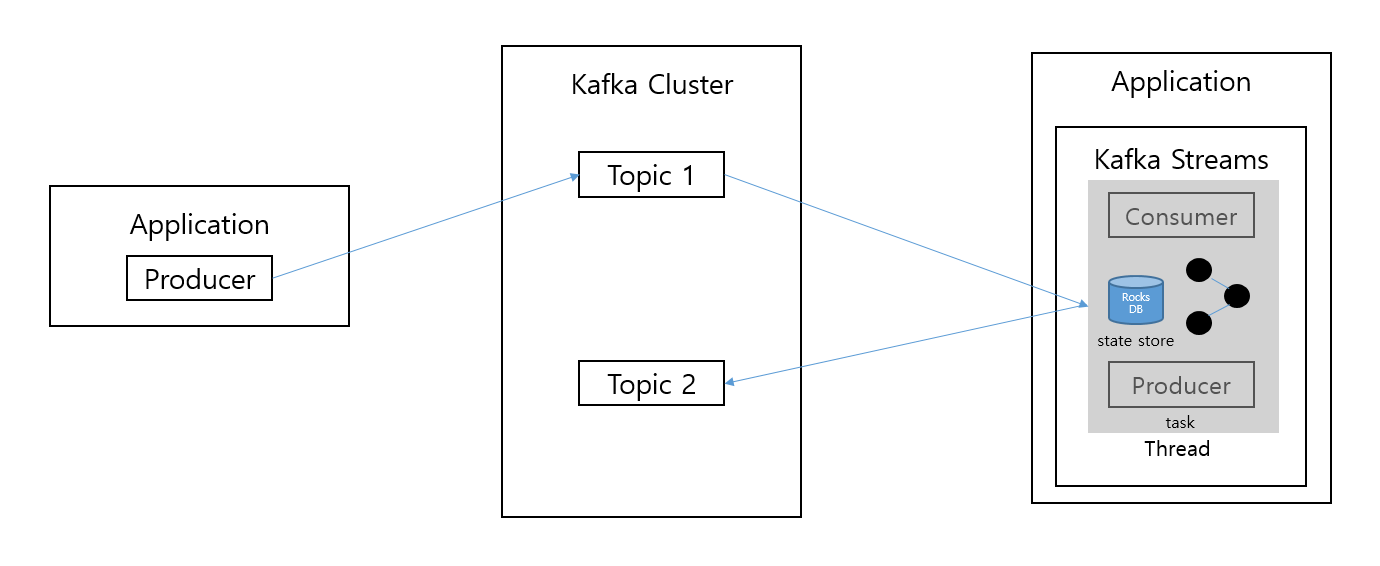
- streams 라이브러리를 통해 제공하는 단 한번의 데이터 처리, 장애 허용 시스템 등의 특징들은 컨슈머와 프로듀서 조합만으로 완벽하게 구현 어려움
- source topic, sink topic이 다른 카프카 클러스터인 경우 streams 지원하지 않으므로 producer, consumer 사용
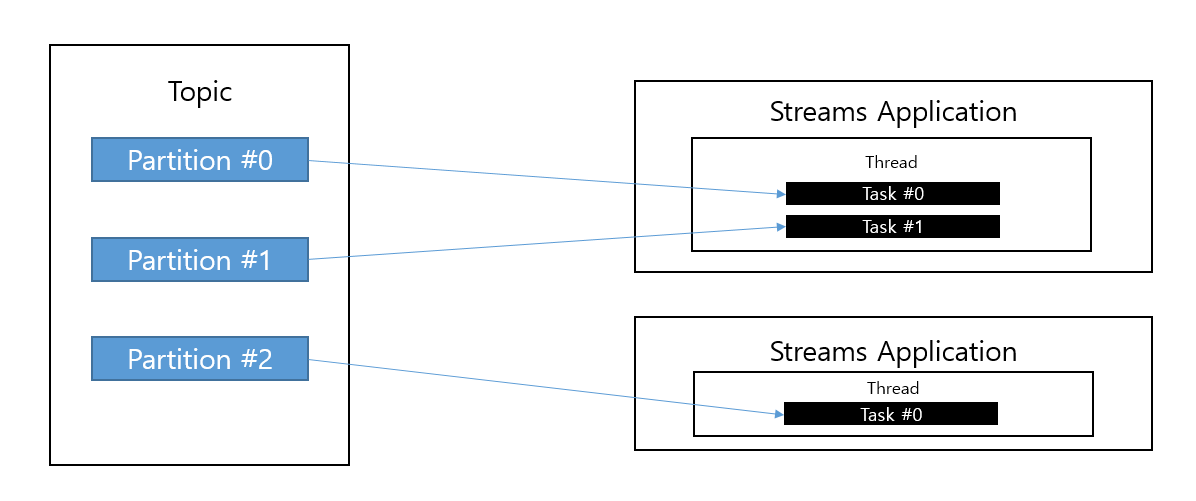
- 스트림즈 애플리케이션은 내부적으로 스레드 1개 이상 생성 가능하고, 스레드는 1개 이상의 태스크를 가짐
- task는 스트림즈 애플리케이션을 실행하면 생기는 데이터 처리 최소 단위
- 만약 3개의 파티션으로 이뤄진 토픽을 처리하는 스트림즈 애플리케이션을 실행하면 내부에 3개의 태스크가 생김
- 스트림즈는 컨슈머 스레드를 늘리는 바업과 동일하게 병렬처리를 위해 토픽 파티션과 스트림즈 thread 개수를 늘림으로써 처리량 늘림
- 스트림즈 애플리케이션은 장애에도 안정적으로 운영 가능하도록 스케일 아웃 가능
토폴로지
- 2개 이상의 노드와 선으로 이루어진 집합
-
스트림즈에서는 트리형과 비슷한 토폴로지 사용
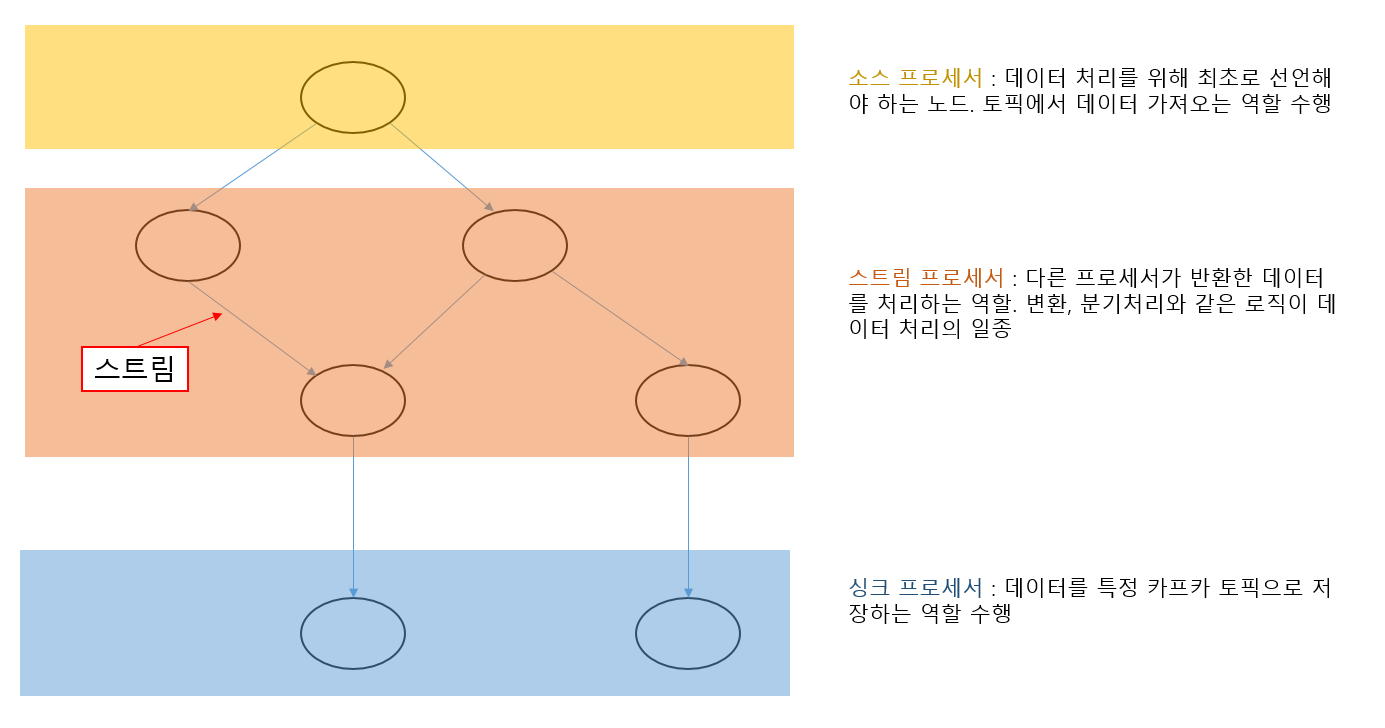
- 토폴로지를 이루는 노드를 하나의 프로세서라고 부름
- 노드와 노드를 이은 선을 스트림이라고 부름
- 스트림은 토픽의 데이터를 의미하는 레코드와 동일한 개념
스트림즈 DSL과 프로세서 API
- 스트림즈 DSL과 프로세서 API 2가지 방법으로 개발 가능
- 스트림즈 DSL은 KTable, KStream 활용
- 프로세서 API는 스트림즈 DSL에서 제공하지 않는 기능, 로직을 Processor 차원의 투박한 코드로 구현 가능
- 스트림즈 DSL의 KTable, KStream 등 개념이 없음
Streams API 기반의 KSQLDB
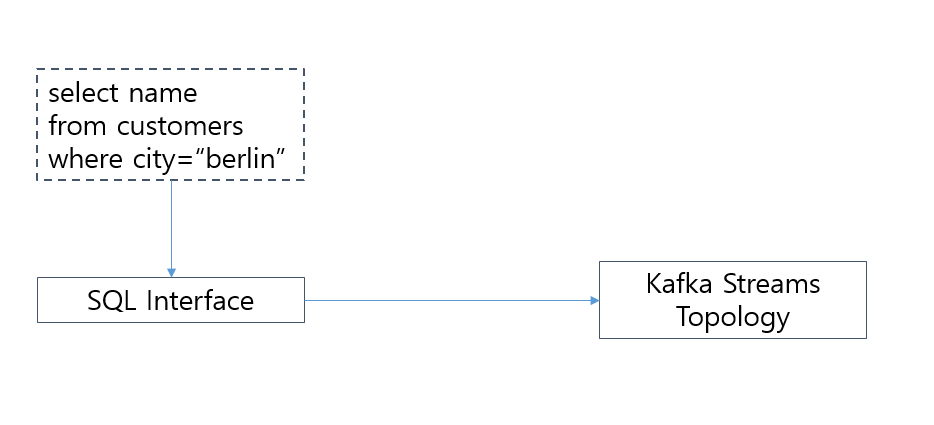
- KsqlDB 기반으로 실시간 Streaming 데이터 처리 중심 축 이동
- 대부분의 Streams API 기능을 KsqlDB로 수행 가능하며 실시간 Streaming 데이터 처리 중심축이 KsqlDB로 급격히 이동
RocksDB 개요
- facebook에서 만든 key-value 기반의 embedded database
- mysql, mongodb의 storage engine으로도 제공됨
- 경량 DB이지만 대용량 데이터에서도 빠른 처리
- 뛰어난 압축 효율, read 뿐만 아니라 특히 write 성능이 뛰어남
- c++로 짜여졌으며 Java로도 interface 제공
- 분산 DB가 아니며 single 노드 DB 엔진임
Kafka 에서의 RocksDB
- kafka의 분산 처리 핵심은 topic의 partition임
- rocksDB는 분산 DB가 아니기 때문에 여러 개의 partition 들이 있을 경우 rocksDB는 개별 partition 별로 구동됨
- streams / ksqlDB 작업 시 partition 별로 rocksDB instance가 생성되어 구동되며 개별 rocksDB는 서로 관여하지 않음
Process, Task, Thread 및 병렬 처리

- 단일 ksqlDB는 하나의 process로 구성됨
- CLI 등으로 SQL이 ksqlDB에서 수행될 떄 해당 SQL이 topology로 재구성됨
- topology는 ksqlDB가 수행해야 할 task로 부여되어 thread가 할당되어 수행됨
- topology는 입력 topic의 partition 수에 따라 sub-topology로 만들어지고 이들이 개별 task로 할당됨
- partition의 개수가 3개인 경우 task도 3개
- ksqlDB에서 일반적으로 task별로 stream thread가 할당되어 작업되나 task 개수가 최대 thread 개수를 초과 시 1개의 stream thread가 여러 개의 task를 수행할 수 있음
- 개별 stream task를 수행하는 개별 stream thread들은 서로 데이터를 주고 받지 않음
ksql.streams.num.stream.threads로 SQL 수행 시 할당되는 threads의 최대 개수를 지정
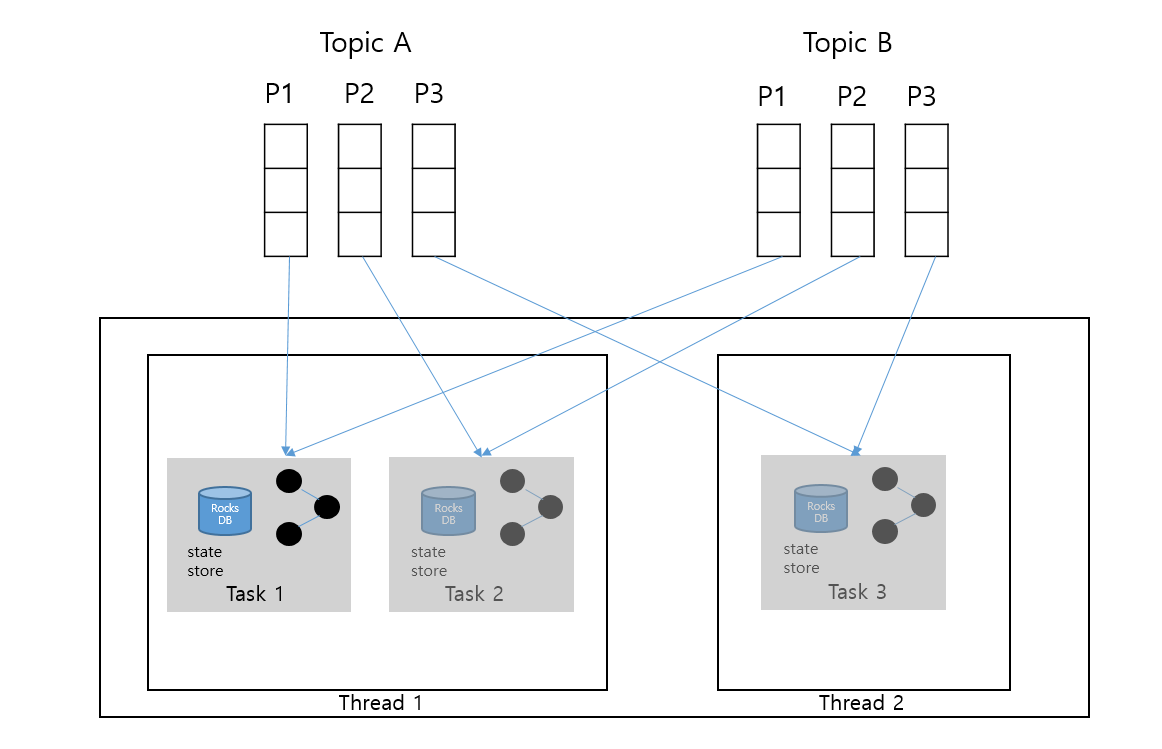
- topic A와 B는 모두 3개의 파티션을 가지므로 3개의 sub topology를 만들고 이를 3개의 task로 생성
- 최대 사용할 수 있는 stream thread가 2개일 경우 3개의 task를 2개의 stream thread에 할당
KsqlDB 환경 설정 및 기동
1) zookeeper 기동
2) kafka 기동
3) schema registry
4) ksqlDB 기동
bootstrap.servers = localhost:9092
ksql.schema.registry.url = http://localhost:8081
- ksql-server.properties 수정